UML
不想多讨论 UML 相关的知识,但是我觉得你如果真的会写 Java,请先学会表达自己,UML 就是你说话的语言,做一名优秀的 Java 程序员,请至少学会这两种 UML 图:
- 类图
- 时序图
clean code
我认为保持代码的简洁和可读性是代码的最基本保证,如果有一天为了程序的效率而降低了这两点,我认为是可以谅解的,除此之外,没有任何理由可以让你任意挥霍你的代码。
- 读者可以看一下 Robert C. Martin 出版的《Clean Code》(代码整洁之道) 这本书
- 可以参考美团文章聊聊 clean code(http://tech.meituan.com/clean-code.html);
- 也可以看一下阿里的 Java 编码规范
无论如何,请保持你的代码的整洁。
Linux 基础命令
这点其实和会写 Java 没有关系,但是 Linux 很多时候确实承载运行 Java 的容器,请学好 Linux 的基础命令。
- 参考鸟哥的《Linux私房菜》
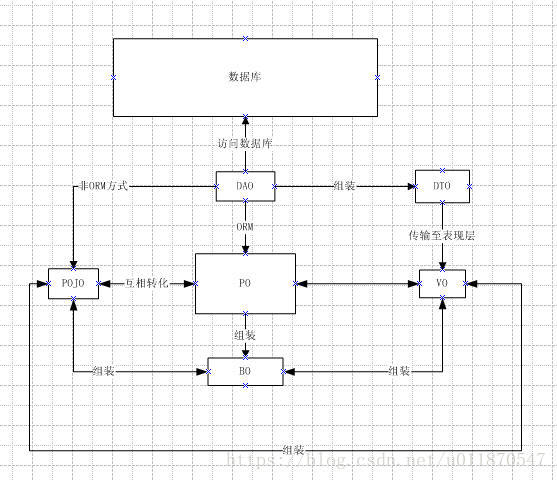
PO:persistent object 持久对象
1 .有时也被称为Data对象,对应数据库中的entity,可以简单认为一个PO对应数据库中的一条记录。
2 .在hibernate持久化框架中与insert/delet操作密切相关。
3 .PO中不应该包含任何对数据库的操作。
POJO :plain ordinary java object 无规则简单java对象
一个中间对象,可以转化为PO、DTO、VO。
1 .POJO持久化之后==〉PO
(在运行期,由Hibernate中的cglib动态把POJO转换为PO,PO相对于POJO会增加一些用来管理数据库entity状态的属性和方法。PO对于programmer来说完全透明,由于是运行期生成PO,所以可以支持增量编译,增量调试。)
2 .POJO传输过程中==〉DTO
3 .POJO用作表示层==〉VO
PO 和VO都应该属于它。
BO:business object 业务对象
业务对象主要作用是把业务逻辑封装为一个对象。这个对象可以包括一个或多个其它的对象。
比如一个简历,有教育经历、工作经历、社会关系等等。我们可以把教育经历对应一个PO,工作经历对应一个PO,社会关系对应一个PO。
建立一个对应简历的BO对象处理简历,每个BO包含这些PO。
这样处理业务逻辑时,我们就可以针对BO去处理。
封装业务逻辑为一个对象(可以包括多个PO,通常需要将BO转化成PO,才能进行数据的持久化,反之,从DB中得到的PO,需要转化成BO才能在业务层使用)。
关于BO主要有三种概念
1 、只包含业务对象的属性;
2 、只包含业务方法;
3 、两者都包含。
在实际使用中,认为哪一种概念正确并不重要,关键是实际应用中适合自己项目的需要。
VO:value object 值对象 / view object 表现层对象
1 .主要对应页面显示(web页面/swt、swing界面)的数据对象。
2 .可以和表对应,也可以不,这根据业务的需要。
DTO(TO):Data Transfer Object 数据传输对象
1 .用在需要跨进程或远程传输时,它不应该包含业务逻辑。
2 .比如一张表有100个字段,那么对应的PO就有100个属性(大多数情况下,DTO内的数据来自多个表)。但view层只需显示10个字段,没有必要把整个PO对象传递到client,这时我们就可以用只有这10个属性的DTO来传输数据到client,这样也不会暴露server端表结构。到达客户端以后,如果用这个对象来对应界面显示,那此时它的身份就转为VO。
DAO:data access object数据访问对象
1 .主要用来封装对DB的访问(CRUD操作)。
2 .通过接收Business层的数据,把POJO持久化为PO。
简易的关系图:
为什么偷来这么一篇文章:不同的对象需要用在不同的地方,之前全是POJO,现在传输用DTO,条件查询用BO,查询对象用POJO接收,显示对象用VO,虽然增加了一点代码量,但是代码结构更加清晰,也防止了表结构的暴露。
个人理解:
po,数据库表字段,一个字段对应一个po
dto,数据传输对象,是从数据库表中查询出来的自定义数据封装。
vo,表现层对象,前端页面显示时所需要的所有数据。由dto组装成vo
如果传输的dto刚好是前端表示所需要的值,此时dto也就是vo。
entity里的每一个字段,与数据库相对应,vo里的每一个字段,是和你前台页面相对应, 而dto,是用类做entity和dto之间转换的实体类。
说到代码结构问题,业务分层
所以一个好的应用分层需要具备以下几点:
方便后续代码进行维护扩展
分层的效果需要让整个团队都接受
各个层职责边界清晰
阿里规范
在阿里的编码规范中约束的分层如下图:
①开放接口层:可直接封装 Service 方法暴露成 RPC 接口;通过 Web 封装成 http 接口;进行网关安全控制、流量控制等。
②终端显示层:各个端的模板渲染并执行显示的层。当前主要是 velocity 渲染,JS 渲染,JSP 渲染,移动端展示等。
③Web 层:主要是对访问控制进行转发,各类基本参数校验,或者不复用的业务简单处理等。
④Service 层:相对具体的业务逻辑服务层。
⑤Manager 层:通用业务处理层。
它有如下特征:
对第三方平台封装的层,预处理返回结果及转化异常信息。
对 Service 层通用能力的下沉,如缓存方案、中间件通用处理。
与 DAO 层交互,对多个 DAO 的组合复用。
⑥DAO 层:数据访问层,与底层 MySQL、Oracle、Hbase 进行数据交互。
下面介绍一下具体业务中应该如何实现分层。
优化分层
从我们的业务开发中总结了一个较为的理想模型,这里要先说明一下由于我们的 RPC 框架选用的是 Thrift 可能会比其他的一些 RPC 框架例如 Dubbo 会多出一层,作用和 controller 层类似。
最上层 Controller 和 TService 是阿里分层规范里面的第一层:轻业务逻辑,参数校验,异常兜底。
通常这种接口可以轻易更换接口类型,所以业务逻辑必须要轻,甚至不做具体逻辑。
①Service:业务层,复用性较低,这里推荐每一个 Controller 方法都得对应一个 Service,不要把业务编排放在 Controller 中去做,为什么呢?
如果我们把业务编排放在 Controller 层去做的话,如果以后我们要接入 Thrift,我们这里又需要把业务编排在做一次,这样会导致我们每接入一个入口层这个代码都得重新复制一份。
如下图所示:
这样大量的重复工作必定会导致我们开发效率下降,所以我们需要把业务编排逻辑都得放进 Service 中去做:
Mannager:可复用逻辑层。这里的 Mannager 可以是单个服务的,比如我们的 Cache,MQ 等等,当然也可以是复合的。
当你需要调用多个 Mannager 的时候,这个可以合为一个 Mannager,比如逻辑上的连表查询等。如果是 httpMannager 或 rpcMannager 需要在这一层做一些数据转换。
③DAO:数据库访问层。主要负责“操作数据库的某张表,映射到某个 Java 对象”,DAO 应该只允许自己的 Service 访问,其他 Service 要访问我的数据必须通过对应的 Service。
分层领域模型的转换
在阿里巴巴编码规约中列举了下面几个领域模型规约:
DO(Data Object):与数据库表结构一一对应,通过 DAO 层向上传输数据源对象。
DTO(Data Transfer Object):数据传输对象,Service 或 Manager 向外传输的对象。
BO(Business Object):业务对象。由 Service 层输出的封装业务逻辑的对象。
AO(Application Object):应用对象。在 Web 层与 Service 层之间抽象的复用对象模型,极为贴近展示层,复用度不高。
VO(View Object):显示层对象,通常是 Web 向模板渲染引擎层传输的对象。
Query:数据查询对象,各层接收上层的查询请求。注意超过2个参数的查询封装,禁止使用 Map 类来传输。
每一个层基本都自己对应的领域模型,这样就导致了有些人过于追求每一层都是用自己的领域模型。
这样就导致了一个对象可能会出现 3 次甚至 4 次转换在一次请求中,当返回的时候同样也会出现 3-4 次转换,这样有可能一次完整的请求-返回会出现很多次对象转换。
如果在开发中真的按照这么来,恐怕就别写其他的了,一天就光写这个重复无用的逻辑算了吧
所以我们得采取一个折中的方案:
允许 Service/Manager 可以操作数据领域模型,对于这个层级来说,本来自己做的工作也是做的是业务逻辑处理和数据组装。
Controller/TService 层的领域模型不允许传入 DAO 层,这样就不符合职责划分了。
同理,不允许 DAO 层的数据传入到 Controller/TService。
bean 使我们使用最多的模型之一
domain 包名
根据很多 Java 程序员的”经验”来看,一个数据库表则对应着一个 domain 对象,所以很多程序员在写代码时,包名则使用:com.xxx.domain ,这样写好像已经成为了行业的一种约束,数据库映射对象就应该是 domain。但是你错了,domain 是一个领域对象,往往我们再做传统 Java 软件 Web 开发中,这些 domain 都是贫血模型,是没有行为的,或是没有足够的领域模型的行为的,所以,以这个理论来讲,这些 domain 都应该是一个普通的 entity 对象,并非领域对象,所以请把包名改为:com.xxx.entity。
DTO
数据传输我们应该使用 DTO 对象作为传输对象,这是我们所约定的,因为很长时间我一直都在做移动端 API 设计的工作,有很多人告诉我,他们认为只有给手机端传输数据的时候(input or output),这些对象成为 DTO 对象。
请注意!这种理解是错误的,只要是用于网络传输的对象,我们都认为他们可以当做是 DTO 对象,比如电商平台中,用户进行下单,下单后的数据,订单会发到 OMS 或者 ERP 系统,这些对接的返回值以及入参也叫 DTO 对象。
我们约定某对象如果是 DTO 对象,就将名称改为 XXDTO,比如订单下发OMS:OMSOrderInputDTO。
DTO 转化
正如我们所知,DTO 为系统与外界交互的模型对象,那么肯定会有一个步骤是将 DTO 对象转化为 BO 对象或者是普通的 entity 对象,让 service 层去处理。
场景
比如添加会员操作,由于用于演示,我只考虑用户的一些简单数据,当后台管理员点击添加用户时,只需要传过来用户的姓名和年龄就可以了,后端接受到数据后,将添加创建时间和更新时间和默认密码三个字段,然后保存数据库。
1 | @RequestMapping("/v1/api/user") |
我们只关注一下上述代码中的转化代码,其他内容请忽略:
1 | User user = new User(); |
请使用工具
上边的代码,从逻辑上讲,是没有问题的,只是这种写法让我很厌烦,例子中只有两个字段,如果有 20 个字段,我们要如何做呢? 一个一个进行 set 数据吗?当然,如果你这么做了,肯定不会有什么问题,但是,这肯定不是一个最优的做法。
网上有很多工具,支持浅拷贝或深拷贝的 Utils。举个例子,我们可以使用 org.springframework.beans.BeanUtils#copyProperties 对代码进行重构和优化:
1 | @PostMapping |
BeanUtils.copyProperties 是一个浅拷贝方法,复制属性时,我们只需要把 DTO 对象和要转化的对象两个的属性值设置为一样的名称,并且保证一样的类型就可以了。如果你在做 DTO 转化的时候一直使用 set 进行属性赋值,那么请尝试这种方式简化代码,让代码更加清晰!
转化的语义
上边的转化过程,读者看后肯定觉得优雅很多,但是我们再写 Java 代码时,更多的需要考虑语义的操作,再看上边的代码:
1 | User user = new User(); |
虽然这段代码很好的简化和优化了代码,但是他的语义是有问题的,我们需要提现一个转化过程才好,所以代码改成如下:
1 | @PostMapping |
这是一个更好的语义写法,虽然他麻烦了些,但是可读性大大增加了,在写代码时,我们应该尽量把语义层次差不多的放到一个方法中,比如:
1 | User user = convertFor(userInputDTO); |
这两段代码都没有暴露实现,都是在讲如何在同一个方法中,做一组相同层次的语义操作,而不是暴露具体的实现。
抽象接口定义
当实际工作中,完成了几个 API 的 DTO 转化时,我们会发现,这样的操作有很多很多,那么应该定义好一个接口,让所有这样的操作都有规则的进行。
如果接口被定义以后,那么 convertFor 这个方法的语义将产生变化,它将是一个实现类。
看一下抽象后的接口:
1 | public interface DTOConvert<S,T> { |
虽然这个接口很简单,但是这里告诉我们一个事情,要去使用泛型,如果你是一个优秀的 Java 程序员,请为你想做的抽象接口,做好泛型吧。
我们再来看接口实现:
1 | public class UserInputDTOConvert implements DTOConvert { |
我们这样重构后,我们发现现在的代码是如此的简洁,并且那么的规范:
1 | @RequestMapping("/v1/api/user") |
review code
如果你是一个优秀的 Java 程序员,我相信你应该和我一样,已经数次重复 review 过自己的代码很多次了。
我们再看这个保存用户的例子,你将发现,API 中返回值是有些问题的,问题就在于不应该直接返回 User 实体,因为如果这样的话,就暴露了太多实体相关的信息,这样的返回值是不安全的,所以我们更应该返回一个 DTO 对象,我们可称它为 UserOutputDTO:
1 | @PostMapping |
这样你的 API 才更健全。
不知道在看完这段代码之后,读者有是否发现还有其他问题的存在,作为一个优秀的 Java 程序员,请看一下这段我们刚刚抽象完的代码:
1 | User user = new UserInputDTOConvert().convert(userInputDTO); |
你会发现,new 这样一个 DTO 转化对象是没有必要的,而且每一个转化对象都是由在遇到 DTO 转化的时候才会出现,那我们应该考虑一下,是否可以将这个类和 DTO 进行聚合呢,看一下我的聚合结果:
1 | public class UserInputDTO { |
然后 API 中的转化则由:
1 | User user = new UserInputDTOConvert().convert(userInputDTO); |
变成了:
1 | User user = userInputDTO.convertToUser(); |
我们再 DTO 对象中添加了转化的行为,我相信这样的操作可以让代码的可读性变得更强,并且是符合语义的。
再查工具类
再来看 DTO 内部转化的代码,它实现了我们自己定义的 DTOConvert 接口,但是这样真的就没有问题,不需要再思考了吗?
我觉得并不是,对于 Convert 这种转化语义来讲,很多工具类中都有这样的定义,这中 Convert 并不是业务级别上的接口定义,它只是用于普通 bean 之间转化属性值的普通意义上的接口定义,所以我们应该更多的去读其他含有 Convert 转化语义的代码。
我仔细阅读了一下 GUAVA 的源码,发现了 com.google.common.base.Convert 这样的定义:
1 | public abstract class Converter<A, B> implements Function<A, B> { |
从源码可以了解到,GUAVA 中的 Convert 可以完成正向转化和逆向转化,继续修改我们 DTO 中转化的这段代码:
1 | private static class UserInputDTOConvert implements DTOConvert<UserInputDTO,User> { |
修改后:
1 | private static class UserInputDTOConvert extends Converter<UserInputDTO, User> { |
看了这部分代码以后,你可能会问,那逆向转化会有什么用呢?其实我们有很多小的业务需求中,入参和出参是一样的,那么我们变可以轻松的进行转化,我将上边所提到的 UserInputDTO 和 UserOutputDTO 都转成 UserDTO 展示给大家。
DTO:
1 | public class UserDTO { |
API:
1 | @PostMapping |
当然,上述只是表明了转化方向的正向或逆向,很多业务需求的出参和入参的 DTO 对象是不同的,那么你需要更明显的告诉程序:逆向是无法调用的:
1 | private static class UserDTOConvert extends Converter<UserDTO, User> { |
看一下 doBackward 方法,直接抛出了一个断言异常,而不是业务异常,这段代码告诉代码的调用者,这个方法不是准你调用的,如果你调用,我就”断言”你调用错误了。
关于异常处理的更详细介绍,可以参考我之前的文章:如何优雅的设计 Java 异常(http://lrwinx.github.io/2016/04/28/%E5%A6%82%E4%BD%95%E4%BC%98%E9%9B%85%E7%9A%84%E8%AE%BE%E8%AE%A1java%E5%BC%82%E5%B8%B8/) ,应该可以帮你更好的理解异常。
bean 的验证
如果你认为我上边写的那个添加用户 API 写的已经非常完美了,那只能说明你还不是一个优秀的程序员。我们应该保证任何数据的入参到方法体内都是合法的。
为什么要验证
很多人会告诉我,如果这些 API 是提供给前端进行调用的,前端都会进行验证啊,你为什还要验证?
其实答案是这样的,我从不相信任何调用我 API 或者方法的人,比如前端验证失败了,或者某些人通过一些特殊的渠道(比如 Charles 进行抓包),直接将数据传入到我的 API,那我仍然进行正常的业务逻辑处理,那么就有可能产生脏数据!
“对于脏数据的产生一定是致命”,这句话希望大家牢记在心,再小的脏数据也有可能让你找几个通宵!
jsr 303验证
hibernate 提供的 jsr 303 实现,我觉得目前仍然是很优秀的,具体如何使用,我不想讲,因为谷歌上你可以搜索出很多答案!
再以上班的 API 实例进行说明,我们现在对 DTO 数据进行检查:
1 | public class UserDTO { |
API 验证:
1 | @PostMapping |
我们需要将验证结果传给前端,这种异常应该转化为一个 api 异常(带有错误码的异常)。
1 | @PostMapping |
BindingResult 是 Spring MVC 验证 DTO 后的一个结果集,可以参考spring 官方文档(http://spring.io/)。
检查参数后,可以抛出一个“带验证码的验证错误异常”,具体异常设计可以参考如何优雅的设计 Java 异常(http://lrwinx.github.io/2016/04/28/%E5%A6%82%E4%BD%95%E4%BC%98%E9%9B%85%E7%9A%84%E8%AE%BE%E8%AE%A1java%E5%BC%82%E5%B8%B8/)。
拥抱 lombok
上边的 DTO 代码,已经让我看的很累了,我相信读者也是一样,看到那么多的 Getter 和 Setter 方法,太烦躁了,那时候有什么方法可以简化这些呢。
请拥抱 lombok,它会帮助我们解决一些让我们很烦躁的问题
去掉 Setter 和 Getter
其实这个标题,我不太想说,因为网上太多,但是因为很多人告诉我,他们根本就不知道 lombok 的存在,所以为了让读者更好的学习,我愿意写这样一个例子:
1 | @Setter |
看到了吧,烦人的 Getter 和 Setter 方法已经去掉了。
但是上边的例子根本不足以体现 lombok 的强大。我希望写一些网上很难查到,或者很少人进行说明的 lombok 的使用以及在使用时程序语义上的说明。
比如:@Data,@AllArgsConstructor,@NoArgsConstructor..这些我就不进行一一说明了,请大家自行查询资料。
bean 中的链式风格
什么是链式风格?我来举个例子,看下面这个 Student 的 bean:
1 | public class Student { |
仔细看一下 set 方法,这样的设置便是 chain 的 style,调用的时候,可以这样使用:
1 | Student student = new Student() |
相信合理使用这样的链式代码,会更多的程序带来很好的可读性,那看一下如果使用 lombok 进行改善呢,请使用 @Accessors(chain = true),看如下代码:
1 | @Accessors(chain = true) |
这样就完成了一个对于 bean 来讲很友好的链式操作。
静态构造方法
静态构造方法的语义和简化程度真的高于直接去 new 一个对象。比如 new 一个 List 对象,过去的使用是这样的:
1 | List<String> list = new ArrayList<>(); |
看一下 guava 中的创建方式:
1 | List<String> list = Lists.newArrayList(); |
Lists 命名是一种约定(俗话说:约定优于配置),它是指 Lists 是 List 这个类的一个工具类,那么使用 List 的工具类去产生 List,这样的语义是不是要比直接 new 一个子类来的更直接一些呢,答案是肯定的,再比如如果有一个工具类叫做 Maps,那你是否想到了创建 Map 的方法呢:
1 | HashMap<String, String> objectObjectHashMap = Maps.newHashMap(); |
好了,如果你理解了我说的语义,那么,你已经向成为 Java 程序员更近了一步了。
再回过头来看刚刚的 Student,很多时候,我们去写 Student 这个 bean 的时候,他会有一些必输字段,比如 Student 中的 name 字段,一般处理的方式是将 name 字段包装成一个构造方法,只有传入 name 这样的构造方法,才能创建一个 Student 对象。
接上上边的静态构造方法和必传参数的构造方法,使用 lombok 将更改成如下写法(@RequiredArgsConstructor 和 @NonNull):
1 | @Accessors(chain = true) |
测试代码:
1 | Student student = Student.ofName("zs"); |
这样构建出的 bean 语义是否要比直接 new 一个含参的构造方法(包含 name 的构造方法)要好很多。
当然,看过很多源码以后,我想相信将静态构造方法 ofName 换成 of 会先的更加简洁:
1 | @Accessors(chain = true) |
测试代码:
1 | Student student = Student.of("zs"); |
当然他仍然是支持链式调用的:
1 | Student student = Student.of("zs").setAge(24); |
这样来写代码,真的很简洁,并且可读性很强。
使用 builder
Builder 模式我不想再多解释了,读者可以看一下《Head First》(设计模式) 的建造者模式。
今天其实要说的是一种变种的 builder 模式,那就是构建 bean 的 builder 模式,其实主要的思想是带着大家一起看一下 lombok 给我们带来了什么。
看一下 Student 这个类的原始 builder 状态:
1 | public class Student { |
调用方式:
1 | Student student = Student.builder().name("zs").age(24).build(); |
这样的 builder 代码,让我是在恶心难受,于是我打算用 lombok 重构这段代码:
1 | @Builder |
调用方式:
1 | Student student = Student.builder().name("zs").age(24).build(); |
代理模式
正如我们所知的,在程序中调用 rest 接口是一个常见的行为动作,如果你和我一样使用过 spring 的 RestTemplate,我相信你会我和一样,对他抛出的非 http 状态码异常深恶痛绝。详解 Java 中的三种代理模式。
所以我们考虑将 RestTemplate 最为底层包装器进行包装器模式的设计:
1 | public abstract class FilterRestTemplate implements RestOperations { |
然后再由扩展类对 FilterRestTemplate 进行包装扩展:
1 | public class ExtractRestTemplate extends FilterRestTemplate { |
包装器 ExtractRestTemplate 很完美的更改了异常抛出的行为,让程序更具有容错性。在这里我们不考虑 ExtractRestTemplate 完成的功能,让我们把焦点放在 FilterRestTemplate 上,“实现 RestOperations 所有的接口”,这个操作绝对不是一时半会可以写完的,当时在重构之前我几乎写了半个小时,如下:
1 | public abstract class FilterRestTemplate implements RestOperations { |
我相信你看了以上代码,你会和我一样觉得恶心反胃,后来我用 lombok 提供的代理注解优化了我的代码(@Delegate):
1 | @AllArgsConstructor |
这几行代码完全替代上述那些冗长的代码。
是不是很简洁,做一个拥抱 lombok 的程序员吧。
工具类的设计
工具类:存放了某一类事物存放工具方法的类。封装了一些常用Java操作方法,便于重复开发利用
命名:XxxUtil,XxxUtils,XxxTool,XxxHelper,XxxHelpers等 比如:JdbcUtil
工具类存放的包:存放工具类
命名:util,utils,tool,helper,helpers等
工具类如何设计?
工具在开发中只需要存在一份即可
1)如果工具类没有使用static修饰,说明工具方法要用工具类的对象来调用。
此时把工具类设计成单例模式。
2)如果工具类使用static修饰,说明工具方法只需要用工具类的类名来调用即可。
此时必须把工具类的构造方法私有化(防止工具类的对象来调用静态方法)。
一般首选第二种,简单,在JDK中提供的工具类都是第二种。如java.Util.Arrays类。
1.如果工具类中的方法全部是静态方法,那么可以将工具类作为一个 abstract 抽象类。Spring 框架中存在大量的这样的使用。
2.如果工具类中有异常,请抛出,不要自己去 try-catch。更不要 try 了之后 e.printStackTrace() 。
3.工具类中要不要打印日志问题,尽量不要打印,像 log4j 这样的一些第三方日志框架也不要用。降低于第三方类库的依赖。
4.工具类中的方法非 static 的。那你可以将工具类定义为 final class,考虑到工具类应该不能被继承。在私有化它的构造函数,提供一个单例。
5.工具类的命名应该用 Util 结尾,例如 LogUtil。
工具类中的方法应该设计为静态的还是非静态的,这个没有统一的标准。各有各的好,参加大多数开源框架,static 的多一些。
工具类的设计,推荐大家多看看 Guava、Apache Commons。
像大名鼎鼎的 Hutool,它提到了工具类的 6 大设计思想:
方法优先于对象、自动识别优于用户定义、便捷性与灵活性并存、适配与兼容、可选依赖原则、无侵入原则。
Hutool 中的工具类,既没有采用抽象类 abstract class 有没有采用 final class。所以我更喜欢 Spring、Guava、Apache Commons等框架的源码。
权限的设计
权限控制主要分为两块,认证(Authentication)与授权(Authorization)。认证之后确认了身份正确,业务系统就会进行授权,现在业界比较流行的模型就是RBAC(Role-Based Access Control)。
RBAC包含为下面四个要素:用户、角色、权限、资源。用户是源头,资源是目标,用户绑定至角色,资源与权限关联,最终将角色与权限关联,就形成了比较完整灵活的权限控制模型。
资源是最终需要控制的标的物,但是我们在一个业务系统中要将哪些元素作为待控制的资源呢?我将系统中待控制的资源分为三类:
- URL访问资源(接口以及网页)
- 界面元素资源(增删改查导入导出的按钮,重要的业务数据展示与否等)
- 数据资源

用户对应角色,(用户多的时候可以用用户组扩展),角色对应多个权限,权限对应多个资源(每个资源都有各自的表和其维护表),权限操作需要有记录表
现在业内普遍的实现方案实际上很粗放,就是单纯的“菜单控制”,通过菜单显示与否来达到控制权限的目的。
我仔细分析过,现在大家做的平台分为To C和To B两种:
- To C一般不会有太多的复杂权限控制,甚至大部分连菜单控制都不用,全部都可以访问。
- To B一般都不是开放的,只要做好认证关口,能够进入系统的只有内部员工。大部分企业内部的员工互联网知识有限,而且作为内部员工不敢对系统进行破坏性的尝试。
所以针对现在的情况,考虑成本与产出,大部分设计者也不愿意在权限上进行太多的研发力量。
菜单和界面元素一般都是由前端编码配合存储数据实现,URL访问资源的控制也有一些框架比如SpringSecurity,Shiro。
目前我还没有找到过数据权限控制的框架或者方法,所以自己整理了一份。
数据权限控制原理
数据权限控制最终的效果是会要求在同一个数据请求方法中,根据不同的权限返回不同的数据集,而且无需并且不能由研发编码控制。这样大家的第一想法应该就是AOP,拦截所有的底层方法,加入过滤条件。这样的方式兼容性较强,但是复杂程度也会更高。我们这套系统中,采用的是利用Mybatis的plugin机制,在底层SQL解析时替换增加过滤条件。
这样一套控制机制存在很明显的优缺点,首先缺点:
- 适用性有限,基于底层的Mybatis。
- 方言有限,针对了某种数据库(我们使用Mysql),而且由于需要在底层解析处理条件所以有可能造成不同的数据库不能兼容。当然Redis和NoSQL也无法限制。
当然,假如你现在就用Mybatis,而且数据库使用的是Mysql,这方面就没有太大影响了。
接下来说说优点:
- 减少了接口数量及接口复杂度。原本针对不同的角色,可能会区分不同的接口或者在接口实现时利用流程控制逻辑来区分不同的条件。有了数据权限控制,代码中只用写基本逻辑,权限过滤由底层机制自动处理。
- 提高了数据权限控制的灵活性。例如原本只有主管能查本部门下组织架构/订单数据,现在新增助理角色,能够查询本部门下组织架构,不能查询订单。这样的话普通的写法就需要调整逻辑控制,使用数据权限控制的话,直接修改配置就好。
数据权限实现
上一节就提及了实现原理,是基于Mybatis的plugins(查看官方文档)实现。
MyBatis 允许你在已映射语句执行过程中的某一点进行拦截调用。默认情况下,MyBatis 允许使用插件来拦截的方法调用包括:
Executor (update, query, flushStatements, commit, rollback, getTransaction, close, isClosed)
ParameterHandler (getParameterObject, setParameters)
ResultSetHandler (handleResultSets, handleOutputParameters)
StatementHandler (prepare, parameterize, batch, update, query)
Mybatis的插件机制目前比较出名的实现应该就是PageHelper项目了,在做这个实现的时候也参考了PageHelper项目的实现方式。所以权限控制插件的类命名为PermissionHelper。
机制是依托于Mybatis的plugins机制,实际SQL处理的时候基于jsqlparser这个包。
设计中包含两个类,一个是保存角色与权限的实体类命名为PermissionRule,一个是根据实体变更底层SQL语句的主体方法类PermissionHelper。
首先来看下PermissionRule的结构:
1 | public class PermissionRule { |
看完这个结构,基本能够理解设计的思路了。数据结构中保存如下几个字段:
- 角色列表:需要使用此规则的角色,可以多个,使用英文逗号隔开。
- 实体列表:对应的规则应用的实体(这里指的是表结构中的表名,可能你的实体是驼峰而数据库是蛇形,所以这里要放蛇形那个),可以多个,使用英文逗号隔开。
- 表达式:表达式就是数据权限控制的核心了。简单的说这里的表达式就是一段SQL语句,其中设置了一些可替换值,底层会用对应运行时的变量替换对应内容,从而达到增加条件的效果。
- 规则说明:单纯的一个说明字段。
核心流程
系统启动时,首先从数据库加载出所有的规则。底层利用插件机制来拦截所有的查询语句,进入查询拦截方法后,首先根据当前用户的权限列表筛选出PermissionRule列表,然后循环列表中的规则,对语句中符合实体列表的表进行条件增加,最终生成处理后的SQL语句,退出拦截器,Mybatis执行处理后SQL并返回结果。
讲完PermissionRule,再来看看PermissionHelper,首先是头:
1 |
|
头部只是标准的Mybatis拦截器写法,注解中的Signature决定了你的代码对哪些方法拦截,update实际上针对修改(Update)、删除(Delete)生效,query是对查询(Select)生效。
下面给出针对Select注入查询条件限制的完整代码:
1 | private String processSelectSql(String sql, List<PermissionRule> rules, UserDefaultZimpl principal) { |
重点思路
重点其实就在于Sql的解析和条件注入,使用开源项目JSqlParser。
- 解析出MainTable和JoinTable。from之后跟着的称为MainTable,join之后跟着的称为JoinTable。这两个就是我们PermissionRule需要匹配的表名,PermissionRule::fromEntity字段。
- 解析出MainTable的where和JoinTable的on后面的条件。使用and连接原本的条件和待注入的条件,PermissionRule::exps字段。
- 使用当前登录的用户信息(放在缓存中),替换条件表达式中的值。
- 某些情况需要忽略权限,可以考虑使用ThreadLocal(单机)/Redis(集群)来控制。
想要达到无感知的数据权限控制,只有机制控制这么一条路。本文选择的是通过底层拦截Sql语句,并且针对对应表注入条件语句这么一种做法。应该是非常经济的做法,只是基于文本处理,不会给系统带来太大的负担,而且能够达到理想中的效果。大家也可以提出其他的见解和思路
电商项目
SPU表

标题(商品名称),副标题(商品描述),几个ID(所属的目录),是否上架,是否有效,添加时间,删除时间。
SKU表

spu_id,商品标题,图片(多个以,分开),销售价格,参数,是否有效,创建时间和修改时间。
kind表
商品的种类,上级菜单分类
订单号的生成
常见的订单基本都14-20位,(年月日时分秒和随机数)基本上就有14位
要求:
1.全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
2.趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
3.单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
4.信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
123对应三类不同的场景,3和4需求还是互斥的,无法使用同一个方案满足
所以ID生产系统:
1.平均延迟和TP999延迟都要尽可能低;
2.可用性5个9;
3.高QPS。
考虑客户体验:
1.订单号无重复性;
2.如果方便客服的话,最好是“日期+自增数”样式的订单号,客服一看便知道订单是否在退货保障期限内容;
3.订单号长度尽量保持短(10位以内),方便用户,尤其电话投诉时,长的号码报错几率高,影响客服效率;
4.订单号尽量保持数字型(纯整数),在数据库订单索引查询中,长整数字型的数据索引与检索效率,远远高于文本型,因此尽量避免“字母+数字字符串式”!
在复杂的分布式系统中,很多场景需要的都是全局唯一ID的场景,一般为了防止冲突可以考虑的有36位的UUID,twitter的snowflake(雪花算法)等。
- UUID, 组成:当前日期+时间+时钟序列+机器识别号(Mac地址或其他)没有mac网卡的话会有别的东西识别。在分布式系统中,所有元素(WEB服务器)都不需要通过中央控制端来判断数据唯一性。几十年之内可以达到全球唯一性。
- Mysql通过AUTO_INCREMENT实现、Oracle通过Sequence序列实现。在数据库集群环境下,不同数据库节点可设置不同起步值、相同步长来实现集群下生产全局唯一、递增ID
- Snowflake算法 雪花算法。41位时间戳+10位机器ID+12位序列号(自增) 转化长度为18位的长整型。Twitter为满足美秒上万条消息的创建,且ID需要趋势递增,方便客户端排序。Snowflake虽然有同步锁,但是比uuid效率高。
- Redis自增ID。实现了incr(key)用于将key的值递增1,并返回结果。如果key不存在,创建默认并赋值为0。 具有原子性,保证在并发的时候。
- 拼接应用所在的网络ip。或者应用所在的端口号。或者进程ID。或者以上的组合保证唯一。
例:
0/1:0为游客下单,1为公司下单
- 商户ID的传入(传入商户ID是为了防止重复订单的,但是不起作用)
- 毫秒仅保留三位(缩减长度同时保证应用切换不存在重复的可能)
- 使用线程安全的计数器做数字递增(三位数最低保证并发800不重复,代码中我给了4位)
- 更换日期转换为java8的日期类以格式化(线程安全及代码简洁性考量)
1 | /** 订单号生成(NEW) **/ |
雪花算法:100万个ID 耗时2秒

1 | public class IdWorker { |
一致性和性能的思考
1、性能和一致性不能同时满足,为了性能考虑,通常会采用「最终一致性」的方案
2、掌握缓存和数据库一致性问题,核心问题有 3 点:缓存利用率、并发、缓存 + 数据库一起成功问题
3、失败场景下要保证一致性,常见手段就是「重试」,同步重试会影响吞吐量,所以通常会采用异步重试的方案
4、订阅变更日志的思想,本质是把权威数据源(例如 MySQL)当做 leader 副本,让其它异质系统(例如 Redis / Elasticsearch)成为它的 follower 副本,通过同步变更日志的方式,保证 leader 和 follower 之间保持一致
项目的思考
1.如果前端需要多个DTO,而不同业务的DTO有99%可以复用,我是需要根据业务生成多个DTO(一个接口一个DTO)传还是都复用一个DTO(多个接口公用一个DTO,虽然很多属性没有用到)?
答:
2.向项目里使用新技术时,我在加的时候是否需要重写之前的方法以适用新技术?这是否违反了开闭原则?
答:
3.如果业务里只有一个方法需要处理,需要等待这个方法的结果再返回给前端,还是异步这个方法,交给其他线程去处理?哪种客户体验更好?
答:
4.web端项目后端怎么主动发消息给前端?前端可能关闭了网页则连接就断了
答:
5.延时处理:过期自动收货,到期自动删除?
答:
6.springboot项目的DTO和VO的分类?Controller层、Service层代码应该放什么?Service层的接口是否真的有必要?
7.业务代码里重复的方法太多,不知道怎么提取公共部分,如果提取了公共部分,一些切面就无法执行,如果为了执行再加切面,是否会影响性能?如果存在两个方法的大致逻辑都一样,只是一些不一样,我该怎么抽取公共?比如说一个方法A,参数是1,业务里根据参数1查对应的表得出11,在根据11继续逻辑;方法B,参数是2,业务里根据参数2查对应的表得出22,在根据22继续逻辑。11和22是不同的表,我该怎么抽取公共代码?
8.功能重要还是性能重要?比如加一个新东西可以实现某项功能,但是会严重消耗性能,我该怎么取舍?(这个功能可能有用可能鸡肋,这个功能和性能的平衡点在哪)
9.对于一个新功能或者新技术的引用,可能会耗费大量时间,在这期间产品不会更新或者进度很慢,是否值得?(怎么向老板解释长时间不出活是为了后期更高的性能)