Spring Boot 是基于Spring的一套快速开发整合包。
Spring Boot 简化了基于Spring的应用开发,只需要“run”就能创建一个独立的、生产级别的Spring应用。Spring Boot为Spring平台及第三方库提供开箱即用的设置(提供默认设置),这样我们就可以简单的开始。多数SpringBoot应用只需要很少的Spring配置。
2.3.2 用途介绍
Spring Boot的核心思想就是约定大于配置,一切自动完成。采用 Spring Boot可以大大的简化你的开发模式,所有你想集成的常用框架,它都有对应的组件支持。你甚至都不用额外的WEB容器,直接生成jar包执行即可,因为spring-boot-starter-web模块中包含有一个内置tomcat,可以直接提供容器使用;基于Spring Boot,不是说原来的配置没有了,而是Spring Boot有一套默认配置,我们可以把它看做比较通用的约定,而Spring Boot遵循的也是约定优于配置原则,同时,如果你需要使用到Spring以往提供的各种复杂但功能强大的配置功能,SpringBoot一样支持
在Spring Boot中,你会发现你引入的所有包都是starter形式,如:
· spring-boot-starter-web-services,针对SOAP Web Services
· spring-boot-starter-web,针对Web应用与网络接口
· spring-boot-starter-jdbc,针对JDBC
· spring-boot-starter-data-jpa,一套JPA应用框架
· spring-boot-starter-cache,针对缓存支持
· 等等
Spring Boot对starter的解释如下:
Starters are a set of convenient dependency descriptors that you can include in your application. You get a one-stop-shop for all the Spring and related technology that you need, without having to hunt through sample code and copy paste loads of dependency descriptors. For example, if you want to get started using Spring and JPA for database access, just include the spring-boot-starter-data-jpa dependency in your project, and you are good to go
这句话的译意为:
Starters是一系列极其方便的依赖描述,通过在你的项目中包含这些starter,你可以一站式获得你所需要的服务,而无需像以往那样copy各种示例配置及代码,然后调试,真正做到开箱即用;比如你想使用Spring JPA进行数据操作,只需要在你的项目依赖中引入spring-boot-starter-data-jpa即可。
2.3.3 主要目标
1.为所有Spring的开发提供一个从根本上更快的入门体验
2.开箱即用,但通过自己设置参数,即可快速摆脱这种方式。
3.提供了一些大型项目中常见的非功能性特性,如内嵌服务器、安全、指标,健康检测、外部化配置等
4.绝对没有代码生成,也无需 XML 配置。
SpringBoot会使用内置的tomcat
SpringBoot的启动主要是通过实例化SpringApplication来启动的,启动过程主要做了以下几件事情:配置属性、获取监听器,发布应用开始启动事件初、始化输入参数、配置环境,输出banner、创建上下文、预处理上下文、刷新上下文、再刷新上下文、发布应用已经启动事件、发布应用启动完成事件。在SpringBoot中启动tomcat的工作在刷新上下这一步。而tomcat的启动主要是实例化两个组件:Connector、Container,一个tomcat实例就是一个Server,一个Server包含多个Service,也就是多个应用程序,每个Service包含多个Connector和一个Container,而一个Container下又包含多个子容器
约定大于配置
约定优于配置(convention over configuration),也称作按约定编程,是一种软件设计范式,旨在减少软件开发人员需做决定的数量,获得简单的好处,而又不失灵活性
1.开发人员仅需规定应用中不符合约定的部分
2.在没有规定配置的地方,采用默认配置,以力求最简配置为核心思想
总的来说,上面两条都遵循了推荐默认配置的思想。当存在特殊需求的时候,自定义配置即可。这样可以大大的减少配置工作,这就是所谓的“约定”。
spring boot中的约定:
1.Maven的目录结构。默认有resources文件夹,存放资源配置文件。src-main-resources,src-main-java。默认的编译生成的类都在targe文件夹下面
2.spring boot默认的配置文件必须是,也只能是application.命名的yml文件或者properties文件,且唯一
3.application.yml中默认属性。数据库连接信息必须是以spring: datasource: 为前缀;多环境配置。该属性可以根据运行环境自动读取不同的配置文件;端口号、请求路径等
1 | # 配置端口 |

配置注解
主配置类
1.@SpringBootApplication
Spring boot的主配置类,Spring boot的启动类
@SpringBootApplication是一个复合注解,包含了@SpringBootConfiguration,@EnableAutoConfiguration,@ComponentScan这三个注解,大多数情况下,这3个注解会被同时使用,基于最佳实践,这三个注解就被做了包装@SpringBootApplication注解。
springboot中有着SpringBootServletInitializer这样一个组件,它关系着程序的初始化
Springboot启动项目方式:
1.application.xml启动
默认application启动,在创建项目时自动生成application启动类,直接run执行即可
2.使用外置tomcat启动
默认启动类要继承SpringBootServletInitiailzer类,并复写configure()方法
1 |
|
需要添加本地tomcat并进行配置
SpringBootServletInitializer的执行过程,简单来说就是通过SpringApplicationBuilder构建并封装SpringApplication对象,并最终调用SpringApplication的run方法的过程。
spring boot就是为了简化开发的,也就是用注解的方式取代了传统的xml配置。
SpringBootServletInitializer就是原有的web.xml文件的替代。
使用了嵌入式Servlet,默认是不支持jsp。
SpringBootServletInitializer 可以使用外部的Servlet容器,使用步骤:
·必须创建war项目,需要创建好web项目的目录。
·嵌入式Tomcat依赖scope指定provided。
·编写SpringBootServletInitializer类子类,并重写configure方法。
1 | public class ServletInitializer extends SpringBootServletInitializer |
·开始启动服务器。
jar包和war包启动区别
jar包:执行SpringBootApplication的run方法,启动IOC容器,然后创建嵌入式Servlet容器
war包: 先是启动Servlet服务器,服务器启动Springboot应用(springBootServletInitizer),然后启动IOC容器
SpringBootServletInitializer实例执行onStartup方法的时候会通过createRootApplicationContext方法来执行run方法,接下来的过程就同以jar包形式启动的应用的run过程一样了,在内部会创建IOC容器并返回,只是以war包形式的应用在创建IOC容器过程中,不再创建Servlet容器了。
@SpringBootConfiguration
标注当前类是配置类
会将当前类内声明的一个或多个以@Bean注解标记的方法的实例纳入到srping容器中,并且实例名就是方法名 继承自@Configuration。
@EnableAutoConfiguration
自动配置的注解
自动配置的注解,根据我们添加的组件jar来完成一些默认配置 我们做微服时会添加spring-boot-starter-web这个组件jar的pom依赖,这样配置会默认配置springmvc 和tomcat
@ComponentScan
扫描当前包及其子包下被@Component,@Controller,@Service,@Repository
扫描当前包及其子包下被@Component,@Controller,@Service,@Repository注解标记的类并纳入到spring容器中进行管理。 等价于context:component-scan的xml配置文件中的配置项
2.@ServletComponentScan
filter的实现,用在Spring boot的启动类
Servlet、Filter、Listener 可以直接通过 @WebServlet、@WebFilter、@WebListener 注解自动注册,这样通过注解servlet ,拦截器,监听器的功能而无需其他配置,所以项目中使用到了filter的实现,用到了这个注解。
3.@MapperScan(“dao路径”)
整合Mybatis,用在Spring boot的启动类 @mapper
@Mapper注解与@MapperScan注解有什么关联呢?
- 使用@Mapper,最终Mybatis会有一个拦截器,会自动的把@Mapper注解的接口生成动态代理类。
- 使用@MapperScan配置一个或多个包路径,自动的扫描这些包路径下的类,自动的为它们生成动态代理类。
- @Mapper注解针对的是一个接口一个接口的使用,太麻烦了。
- @MapperScan注解针对的是一个或多个包中的所有接口,相比@Mapper注解来说非常简单。
4.@EnableScheduling
允许schedul定时任务,表明此类是一个定时计划类
@Scheduled(fixedRate = 5000) :要执行的具体计划任务
参数
1.cron:cron表达式语句
2.zone:时区,接收一个java.util.TimeZone#ID。默认空字符串,即取服务器所在的时区
3.fixedDelay:上一次执行完毕多长时间点后多长时间再执行
4.fixedDelayString:与fixedDelay意思相同,只是使用字符串的形式,支持占位符
5.fixedRate:与上一次开始执行时间点之后多长时间再执行
6.fixedRateString:与fixedRate意思相同,只是使用字符串的形式,支持占位符
7.initialDelay:第一次延迟多长时间后再执行
8.initialDelayString :与initialDelay意思相同,只是使用字符串的形式,支持占位符
5.@EnableCaching
使用缓存
6.@EnableTransactionManagement
开启事务注解支持
单元测试常用注解
@RunWith(SpringJUnit4ClassRunner.class)、(SpringRunner.class)
测试类,让测试运行于Spring测试环境。
SpringRunner 继承了SpringJUnit4ClassRunner,没有扩展任何功能;使用SpringRunner,名字简短而已
@SpringBootTest
Springboot环境下测试
@Test
junit单元测试,单元测试方法上 ,方法要求:
1 | public void 方法名() {} //公共方法、无返回值、方法无参数 |
@Ignore:表示这个方法不进行单元测试
@Before: 在每个方法执行运行
@After:在每个方法之后运行
@Before
预加载,测试方法前
@WebAppConfiguration
web应用测试
Controller常用注解
@RestController
用于Controller标识,@Controller 和@ResponseBody的结合
@Controller 表明这个类是一个控制器类,和 @RequestMapping 来配合使用拦截请求,如果不在method中注明请求的方式,默认是拦截get和post请求。这样请求会完成后转向一个视图解析器。但是在大多微服务搭建的时候,前后端会做分离。所以请求后端只关注数据处理,后端返回json数据的话,需要配合 @ResponseBody 注解来完成。
@GetMapping、PostMapping、PutMapping、DeleteMapping
rest风格
| 普通风格 | Rest风格 |
|---|---|
| @RequestMapping(value=“”,method = RequestMethod.GET) | @GetMapping(value =“”) |
@GetMapping Get请求
@PostMapping Post请求
@PutMapping 订单确认
@DeleteMapping 取消订单
@Autowired
按类型自动注入
Restful之swagger
1 | <!-- swagger是当前最好用的Restful --> |
@Api(value = “订单Controller”, tags = {“订单Controller”})
value - 字段说明,description - 注释说明这个类
@ApiOperation(value = “订单确认接口”)
在restful风格方法上配合使用
@ApiOperation(value = “订单取消接口”)
@DeleteMapping(value = “/order/{orderId}”)
1 | 作用范围 API 使用位置 |
配置文件相关
@Value(“${spring.datasource.druid.url}”)
注入配置文件中的值
@ImportResource @Import @PropertySource
用来导入自定义的一些配置文件
@ImportResource(locations={}) 导入其他xml配置文件,需要标准在主配置类上。
导入property的配置文件 @PropertySource指定文件路径,这个相当于使用spring的标签来完成配置项的引入。
@import注解是一个可以将普通类导入到spring容器中做管理
@EnableAsync(proxyTargetClass = true)
异步代理,构建异步线程池
使用@EnableAsync来开启异步的支持,使用@Async来对某个方法进行异步执行
在定时器里可以设置多个不同线程的任务同时完成不同的事情
@Configuration
配置类
@Bean(“analysisExecutor”)
相当于
@Aspect
切面,事务
@Scope(“prototype”)
bean的作用范围,多例,httpclientConfig
@EnableRedisHttpSession(maxInactiveIntervalInSeconds = 1800,redisFlushMode = RedisFlushMode.ON_SAVE, redisNamespace = “dscSession”)
redissession 默认30分钟失效
@EnableWebMvc
用于spring mvc 配置类,启用springmvc
@EnableSwagger2
restful风格,使用Swagger2
dao
@Param(“ids”) Integer[] ids, @Param(“userId”
1 | mapper接口中有多个参数 |
异常处理
@ControllerAdvice
全局异常处理
全局数据绑定
全局数据预处理
@ExceptionHandler(BindException.class)
1、@ExceptionHandler不需要写在目标方法上,而是写在通知处理方法上
2、@ExceptionHandler自动拦截所设置的异常 作用范围这个controller,
—这种情况一般定义个父类,然后每个controller继承即可
lombok插件使用
1 | <dependency> |
@Data
首先在idea中安装lombok插件
@Data : 注解在类上,
就不用再去手写Getter,Setter,equals,canEqual,hasCode,toString等方法了,
注解后在编译时会自动加进去
@NoArgsConstructor @Getter @Setter
使用后创建一个无参构造函数、getter、setter
@AllArgsConstructor
使用后添加一个构造函数,该构造函数含有所有已声明字段属性参数
@Builder
关于Builder较为复杂一些,Builder的作用之一是为了解决在某个类有很多构造函数的情况,也省去写很多构造函数的麻烦,
在设计模式中的思想是:用一个内部类去实例化一个对象,避免一个类出现过多构造函数,
@Accessors
存取器。通过该注解可以控制getter和setter方法的形式,默认为false
1.fluent为一个布尔值,如果为true生成的get/set方法则没有set/get前缀,默认为false
1 | @Data |
2.chain为一个布尔值,如果为true生成的set方法返回this,为false生成的set方法是void类型。默认为false,除非当fluent为true时,chain默认则为true。
这个比较常用,由于set方法返回的是this对象,常用来实现链式编程
1 | user.setName("张三").setAge(12).setHeight(175) |
3.prefix为一系列string类型,可以指定前缀,生成get/set方法时会去掉指定的前缀
1 | @Accessors(prefix = "m") |
监控
@Component
@ConditionalOnProperty(prefix = “dsc”, name=“ticketWatcherMaster”, havingValue = “true”)
监控转换队列是否有超时ticket,如果超时自动补偿ticket
@Scheduled(cron = “0 0/2 * * * ?”)
定期监控,补偿超时的ticket,2分钟执行一次,延迟60秒启动
1 | /*"0 0 12 * * ?" 每天中午十二点触发 |
@WebListener
启动监听器 web监听
事务通知
@Pointcut(value = “execution(* com.yozo.dsc.web….(…))”)
切点
@AfterReturning(value = “webRequest()”)
后置通知
@Around(value = “getFileHeaderBOByHead()”)
环绕通知
@Before(value = “onlineConvert() && args(domainBo,dscOnlineParamBo)”)
前置通知
线程池
@PostConstruct
1 | 初始化邮箱线程池 |
MQ
@RocketMQMessageListener(topic = MQConstant.ConvertFinishMqTopic, consumerGroup = “${rocketmq.consumer.group}”, consumeMode = ConsumeMode.CONCURRENTLY, messageModel = MessageModel.CLUSTERING)
RocketMQ监听
redis
@ConditionalOnBean(RedisConfig.class)
@Qualifier(“dscRedisTemplate”)
@Service(“redisService”)
@Configuration & @Bean
Spring Boot不同于传统的Spring,它不提倡使用配置文件,而是使用配置类来代替配置文件,所以该注解就是用于将一个类指定为配置类:
1 |
|
在配置类中使用方法对组件进行注册,它的效果等价于:
1 | <bean id="user" class="com.wwj.springboot.bean.User"> |
需要注意的是 Spring Boot 默认会以方法名作为组件的id,也可以在 @Bean() 中指定value值作为组件的id。
@Import
在Spring中,我们可以使用@Component、@Controller、@Service、@Repository注解进行组件的注册,而对于一些第三方的类,我们无法在类上添加这些注解,为此,我们可以使用@Import注解将其注册到容器中。
1 |
|
通过@Import注解注册的组件,其id为全类名。
@Conditional
该注解为条件装配注解,大量运用于SpringBoot底层,由该注解衍生出来的注解非常多:
这里以@ConditionalOnBean和@ConditionalOnMissingBean举例。其中@ConditionalOnBean注解的作用是判断当前容器中是否拥有指定的Bean,若有才生效,比如:
1 |
|
若如此,则SpringBoot在注册User对象之前,会先判断容器中是否已经有id为 dog 的对象,若有才创建,否则不创建。@ConditionalOnBean注解共有三种方式判断容器中是否已经存在指定的对象,除了可以判断组件的id外,也能够通过判断组件的全类名:
1 |
|
还可以通过判断组件的类型:
1 |
|
尤其需要注意的是,因为代码是从上至下依次执行的,所以在注册组件时的顺序要特别注意,比如:
1 |
|
在这段程序中,SpringBoot会先注册User对象,而此时Dog对象还没有被注册,所以会导致User对象无法注册。
而@ConditionalOnMissingBean注解的作用与@ConditionalOnBean注解正好相反,它会判断当前容器中是否不存在指定的Bean,若不存在则生效,否则不生效。
这些注解除了能够标注在方法上,还能作用于类上,当被标注在类上时,若条件成立,则配置类的所有注册方法生效;若条件不成立,则配置类的所有注册方法均不成立。
1 |
|
@ImportResource
该注解用于导入资源,比如现在有一个Spring的配置文件:
1 |
|
若是想将其转化为配置类,代码少一点倒还好说,当配置文件中注册的Bean非常多时,采用人工的方式显然不是一个好的办法,为此,SpringBoot提供了@ImportResource注解,该注解可以将Spring的配置文件直接导入到容器中,自动完成组件注册。
1 |
|
@ConfigurationProperties
该注解用于配置绑定,也大量运用于SpringBoot底层。首先在配置文件中编写两个键值:
1 | user.name=zhangsan |
然后使用该注解将其绑定到User类上:
1 |
|
但结果却有些出乎意料:
1 | User{name='Administrator', age=30} |
这是因为我们将前缀 prefix 指定为了user,而user可能和我们的系统配置产生了重复,所以导致了这个问题,此时我们只需将前缀修改一下即可:
1 |
|
前缀修改了,配置文件的内容也需要做相应的修改:
1 | users.name=zhangsan |
需要注意的是,若是想实现配置绑定,就必须要将这个待绑定的类注册到容器中,比如使用@Component注解,当然,SpringBoot也提供了一个注解与其配套使用,它就是:@EnableConfigurationProperties
该注解必须标注在配置类上:
1 |
|
作用是开启指定类的配置绑定功能,它的底层其实也是通过@Import注解实现的,此时User类就无需将其注册到容器中:
1 |
|
Spring Boot 会自动将属性值绑定到 User 类,并将其注册到容器中。Spring Boot 相关的技术文章我整理成了 PDF,关注微信公众号「Java后端」回复「666」下载这一本技术栈手册。
@Cacheable
@Cacheable 注解在方法上,表示该方法的返回结果是可以缓存的
@Async
当访问的接口较慢或者做耗时任务时,不想程序一直卡在耗时任务上,想程序能够并行执行,我们可以使用多线程来并行的处理任务
在SpringBoot中使用@Async:
1 | 一、异步配置(配置里主要写无返回值的异常处理) |
基于@Async调用中的异常处理机制
在异步方法中,如果出现异常,对于调用者caller而言,是无法感知的。如果确实需要进行异常处理,则按照如下方法来进行处理:
1.自定义实现AsyncTaskExecutor的任务执行器
在这里定义处理具体异常的逻辑和方式。
2.配置由自定义的TaskExecutor替代内置的任务执行器
1 | public class ExceptionHandlingAsyncTaskExecutor implements AsyncTaskExecutor { |
可以发现其实实现了AsyncTaskExecutor, 用独立的线程来执行具体的每个方法操作。在createCallable和createWrapperRunnable中,定义了异常的处理方式和机制。
handle()就是我们需要关注的异常处理的地方
配置文件中的内容
1 | <task:annotation-driven executor="exceptionHandlingTaskExecutor" scheduler="defaultTaskScheduler" /> |
这里的配置使用自定义的taskExecutor来替代缺省的TaskExecutor
@Async调用中的事务处理机制
在@Async标注的方法,同时也适用了@Transactional进行了标注;在其调用数据库操作之时,将无法产生事务管理的控制,原因就在于其是基于异步处理的操作。
那该如何给这些操作添加事务管理呢?可以将需要事务管理操作的方法放置到异步方法内部,在内部被调用的方法上添加@Transactional.
例如:
方法A,使用了@Async/@Transactional来标注,但是无法产生事务控制的目的。
方法B,使用了@Async来标注, B中调用了C、D,C/D分别使用@Transactional做了标注,则可实现事务控制的目的。
测试代码:
1 | 1.java的代码是同步顺序执行,当我们需要执行异步操作时我们需要创建一个新线程去执行 |
无返回值的测试:
1 | /** |

有返回值,但主线程不需要用到返回值
1 | /** |

有返回值,且主线程需要用到返回值
1 | /** |

可以发现,有返回值的情况下,虽然异步业务逻辑是由新线程执行,但如果在主线程操作返回值对象,主线程会等待,还是顺序执行
事务测试
1 | /** |


模拟异常,事务回滚
1 | /** |


@Profile
Spring为我们提供的可以根据当前环境,动态的激活和切换一系列组件的功能
@Profile:指定组件在哪个环境的情况下才能被注册到容器中,不指定,任何环境下都能注册这个组件
- 加了环境标识的bean,只有这个环境被激活的时候才能注册到容器中。默认是default环境
- 写在配置类上,只有是指定的环境的时候,整个配置类里面的所有配置才能开始生效
数据库配置
基本配置
JDBC的数据库连接池使用javax.sql.DataSource来表示,DataSource只是一个接口,该接口通常由服务器(Weblogic,WebSphere,Tomcat)提供实现,也有一些开源组织提供实现,如:DBCP数据库连接池、C3P0数据库连接池、Proxpool数据库连接池.
对象采用池化的原因:采用池化的本意是通过减少对象生成的次数,减少花在对象初始化上面的开销,从而提高整体性能。
使用数据库连接池的优点:
1)资源重用:
由于数据库连接得以重用,避免了频繁创建,释放连接引起的大量性能开销。在减少系统消耗的基础上,另一方面也增加了系统运行环境的平稳性。
2)更快的系统反应速度
数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于连接池中备用。此时连接的初始化工作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了数据库连接初始化和释放过程的时间开销,从而减少了系统的响应时间。
3)新的资源分配手段
对于多应用共享同一数据库的系统而言,可在应用层通过数据库连接池的配置,实现某一应用最大可用数据库连接数的限制,避免某一应用独占所有的数据库资源。
4)统一的连接管理,避免数据库连接泄露
在较为完善的数据库连接池实现中,可根据预先的占用超时设定,强制回收被占用连接,从而避免了常规数据库连接操作中可能出现的资源泄露。
Springboot默认数据库连接池为 Tomcat JDBC Pool
1 | #初始化连接 |
wait_timeout需要设置成很大一个值:
如果wait_timeout设置成很小,如1分钟。因为服务器1分钟就把空闲连接断开了,客户端过了5分钟再去检查连接情况,那有什么意义?先前就是没理解被误导了,把timeBetweenEvictionRunsMillis设置了一个比较大的值,所以一直有问题。包括所说的8小时问题也是源于此(mysql数据库默认是空闲8小时断开)
连接池配置中的timeBetweenEvictionRunsMillis和minEvictableIdleTimeMillis的时间小于或者等于mysql数据库中wait_timeout的时间
多数据库源配置
参考文章:https://www.cnblogs.com/aizen-sousuke/p/11756279.html
maven依赖:
1 | spring-boot-starter-web |
代码:
1 | //1.配置文件application.properties,配置了2个库的连接 |
缓存
缓存不关心方法的执行逻辑,它能确定的是:对于同一个方法,如果参数相同,那么返回结果也是相同的。但是如果参数不同,缓存只能假设结果是不同的,所以对于同一个方法,你的程序运行过程中,使用了多少种参数组合调用过该方法,理论上就会生成多少个缓存的 key(当然,这些组合的参数指的是与生成 key 相关的)
cacheNames/value
@Cacheable 提供两个参数来指定缓存名:value、cacheNames,二者选其一即可 @Cacheable("menu")
@Cacheable 支持同一个方法关联多个缓存。这种情况下,当执行方法之前,这些关联的每一个缓存都会被检查,而且只要至少其中一个缓存命中了,那么这个缓存中的值就会被返回 @Cacheable({"menu", "menuById"})
key&keyGenerator
一个缓存名对应一个被注解的方法,但是一个方法可能传入不同的参数,那么结果也就会不同,需要用到 key 。
在 spring 中,key 的生成有两种方式:显式指定和使用 keyGenerator 自动生成
1.spring 官方更推荐显式指定 key 的方式,即指定 @Cacheable 的 key 参数,使用SpEL(Spring Expression Language,Spring 表达式语言)
@Cacheable(value = {"menuById"}, key = "#id")
@Cacheable(value = {"menuById"}, key = "'id-' + #menu.id")
@Cacheable(value = {"menuById"}, key = "'hash' + #menu.hashCode()")

2.当我们在声明 @Cacheable 时不指定 key 参数,则该缓存名下的所有 key 会使用 KeyGenerator 根据参数 自动生成。spring 有一个默认的 SimpleKeyGenerator ,在 spring boot 自动化配置中,这个会被默认注入。生成规则如下:
a. 如果该缓存方法没有参数,返回 SimpleKey.EMPTY ;
b. 如果该缓存方法有一个参数,返回该参数的实例 ;
c. 如果该缓存方法有多个参数,返回一个包含所有参数的 SimpleKey ;
默认的 key 生成器要求参数具有有效的 hashCode() 和 equals() 方法实现。另外,keyGenerator 也支持自定义, 并通过 keyGenerator 来指定。关于 KeyGenerator,其实就是使用 hashCode 进行加乘运算。跟 String 和 ArrayList 的 hash 计算类似。
注:key 和 keyGenerator 参数是互斥的,同时指定两个会导致异常
cacheManager
CacheManager,缓存管理器是用来管理(检索)一类缓存的。通常来讲,缓存管理器是与缓存组件类型相关联的。我们知道,spring 缓存抽象的目的是为使用不同缓存组件类型提供统一的访问接口,以向开发者屏蔽各种缓存组件的差异性。那么 CacheManager 就是承担了这种屏蔽的功能。spring 为其支持的每一种缓存的组件类型提供了一个默认的 manager,如:RedisCacheManager 管理 redis 相关的缓存的检索、EhCacheManager 管理 ehCache 相关的缓等。
cacheResolver
CacheResolver,缓存解析器是用来管理缓存管理器的,CacheResolver 保持一个 cacheManager 的引用,并通过它来检索缓存。CacheResolver 与 CacheManager 的关系有点类似于 KeyGenerator 跟 key。spring 默认提供了一个 SimpleCacheResolver,开发者可以自定义并通过 @Bean 来注入自定义的解析器,以实现更灵活的检索。
大多数情况下,我们的系统只会配置一种缓存,所以我们并不需要显式指定 cacheManager 或者 cacheResolver。但是 spring 允许我们的系统同时配置多种缓存组件,这种情况下,我们需要指定。指定的方式是使用 @Cacheable 的 cacheManager 或者 cacheResolver 参数。
注意:按照官方文档,cacheManager 和 cacheResolver 是互斥参数,同时指定两个可能会导致异常。
sync
是否同步,true/false。在一个多线程的环境中,某些操作可能被相同的参数并发地调用,这样同一个 value 值可能被多次计算(或多次访问 db),这样就达不到缓存的目的。针对这些可能高并发的操作,我们可以使用 sync 参数来告诉底层的缓存提供者将缓存的入口锁住,这样就只能有一个线程计算操作的结果值,而其它线程需要等待,这样就避免了 n-1 次数据库访问。
sync = true 可以有效的避免缓存击穿的问题
condition
调用前判断,缓存的条件。有时候,我们可能并不想对一个方法的所有调用情况进行缓存,我们可能想要根据调用方法时候的某些参数值,来确定是否需要将结果进行缓存或者从缓存中取结果。比如当我根据年龄查询用户的时候,我只想要缓存年龄大于 35 的查询结果。那么 condition 能实现这种效果。
condition 接收一个结果为 true 或 false 的表达式,表达式同样支持 SpEL 。如果表达式结果为 true,则调用方法时会执行正常的缓存逻辑(查缓存-有就返回-没有就执行方法-方法返回不空就添加缓存);否则,调用方法时就好像该方法没有声明缓存一样(即无论传入了什么参数或者缓存中有些什么值,都会执行方法,并且结果不放入缓存)
@Cacheable(value = {"menuById"}, key = "#id", condition = "#conditionValue > 1")
unless
执行后判断,不缓存的条件。unless 接收一个结果为 true 或 false 的表达式,表达式支持 SpEL。当结果为 true 时,不缓存
@Cacheable(value = {"menuById"}, key = "#id", unless = "#result.type == 'folder'")
condition 不指定相当于 true,unless 不指定相当于 false
当 condition = false,一定不会缓存;
当 condition = true,且 unless = true,不缓存;
当 condition = true,且 unless = false,缓存;
实际使用遇到的问题:
1.同一个类,其中一个方法调用另一个注解缓存的方法时,不走缓存。
2.缓存的对象会存往redis,存入redis的对象必须实现序列化接口,否则存入的是乱码或者二进制字符。
事务
事务管理器
事务的打开、回滚和提交是由事务管理器来完成的。在Spring中,事务管理器的顶层接口为PlatformTransactionManager,Spring也定义了一些其他的接口和类。
在Spring Boot中,当你依赖于mybatis-spring-boot-starter之后,它会自动创建一个DataSource TransactionManager对象作为事务管理器;
如果依赖于spring-boot-starter-data-jpa,则它会自动创建JpaTransactionManager对象作为事务管理器,所以我们一般不需要自己创建事务管理器而直接使用它们即可
@Transactional
声明式事务,@Transactional 注解应该只被应用到 public 方法上,这是由 Spring AOP 的本质决定的,
涉及到两张表以上的更新或者删除操作,为了保证数据库的一致性,需要添加 @Transactional事务注解,否则程序会抛出异常
(@Scheduled 和@Transactional不能同时存在一个类里面)
源码分析
1 |
|


@Transaction 默认配置适合80%的配置,特殊场景的配置需要手动配置参数
Spring的默认的事务规则是遇到运行异常(RuntimeException)和程序错误(Error)才会回滚。
其他异常回滚
Spring默认情况下会对(RuntimeException)及其子类来进行回滚,在遇见Exception及其子类的时候则不会进行回滚操作
如果想针对非检测异常(即运行异常)进行事务回滚,可以在@Transactional 注解里使用,@Transactional(rollbackFor=Exception.class) 属性明确指定异常。
1 | 例如: |
当遇到SQLException时会回滚,遇到RuntimeException和Error也会回滚。(相当于设置后是添加了属性)
嵌套回滚
1 |
|
事务传播性
@Transaction中的propagation的可以配置事务的传播性
常用的传播行为是REQUIRED、REQUIRES_NEW、NESTED三种
1 | //源码分析 |
在事务中读取最新配置
有时候需要在一个事务中,读取最新数据(默认是读取事务开始前的快照)。其实很简单,只要使用上面PROPAGATION_NOT_SUPPORTED传播性就可以了
1 | @Transactional |
事务失效
1.如果你在方法中有try{}catch(Exception e){}处理,那么try里面的代码块就脱离了事务的管理,若要事务生效需要在catch中throw new RuntimeException (“xxxxxx”)
2.在@Transactional注解的方法中,再调用本类中的其他方法method2时,那么method2方法上的@Transactional注解是不会生效的!(也就是下面这个内部调用事务方法模块所讲的解决方法)
内部调用事务方法
事务注解的实质就是在创建一个动态代理,在调用事务方法前开启事务,在事务方法结束以后决定是事务提交还是回滚
Spring数据库事务的实现原理是AOP,而AOP的原理是动态代理。在事务自调用的过程中,是类自身的调用即通过this.指向的目标对象,而不是代理对象去调用,那么就不会产生AOP,这样Spring就不能把你的代码织入到约定的流程中,于是就产生了@Transactional自调用失效的场景。
因此,直接在类内部中调用事务方法,是不会经过动态代理的

因此,如果要使方法B点事务生效:

解决方法1:需要在内部调用方法B的时候,找到当前类的代理类,用代理类去调用方法B
1 | @Service |
解决办法2:在spring中拿Bean的方法
1 | @Service |
tips:spring现在对一些循环依赖是提供支持的,简单来说,满足:
1.Bean是单例
2.注入的方式不是构造函数注入
1 | 通过BeanFactory |
注意:
1.使用@Transaction注解的方法,必须用public来修饰。
2.其实不止是@Transaction,其他类似@Cacheable,@Retryable等依赖spring proxy也必须使用上述方式达到内部调用。
3.@Transactional,@Async放在同一个类中,如果使用Autowire注入会循环依赖,而使用BeanFactoryAware会使得@Transactional无效
4.@Transactional注解保证的是每个方法处在一个事务,如果有try一定在catch中抛出运行时异常
5.this.本方法的调用,被调用方法上注解是不生效的,因为无法再次进行切面增强
6.不仅是执行两个以上增删改数据时需要加事务,如果是两条查询语句,一个增删改语句和一个额外操作,都需要加事务来预防出现查询时不一致,额外操作失败导致语句执行不回滚的情况
总结:
在需要事务回滚的时候,最好还是抛出RuntimeException,并且不要在代码中捕获此类异常
自动配置原理
有了前面的注解基础之后,我们就能够更深入地了解Spring Boot的自动配置原理,自动配置正是建立在这些强大的注解之上的。
我们首先观察一下主启动类上的注解:
1 |
|
翻阅源码可以得知,@SpringBootApplication注解其实是由三个注解组成的:
1 |
|
其中@SpringBootConfiguration底层是@Configuration注解,它表示主启动类是一个配置类;而@ComponentScan是扫描注解,它默认扫描的是主启动类当前包及其子包下的组件;最关键的就是@EnableAutoConfiguration注解了,该注解便实现了自动配置。
查看@EnableAutoConfiguration注解的源码,又会发现它是由两个注解组合而成的:
1 |
|
我们继续查看@AutoConfigurationPackage注解的源码:
1 |
|
@Import注解我们非常熟悉,它是用来导入一个组件的,然而它比较特殊:
1 | static class Registrar implements ImportBeanDefinitionRegistrar, DeterminableImports { |
这里的 Registrar 组件中有两个方法,它是用来导入一系列组件的,而该注解又被间接标注在了启动类上,所以它会将主启动类所在包及其子包下的所有组件均注册到容器中。
接下来我们继续看@EnableAutoConfiguration的第二个合成注解:@Import({AutoConfigurationImportSelector.class}) 该注解也向容器中注册了一个组件,翻阅该组件的源码:
1 | public class AutoConfigurationImportSelector implements DeferredImportSelector, BeanClassLoaderAware, ResourceLoaderAware, BeanFactoryAware, EnvironmentAware, Ordered { |
这个方法是用来选择导入哪些组件的,该方法又调用了getAutoConfigurationEntry()方法得到需要导入的组件,所以我们查看该方法:
1 | protected AutoConfigurationImportSelector.AutoConfigurationEntry getAutoConfigurationEntry(AnnotationMetadata annotationMetadata) { |
在getCandidateConfigurations()方法处打一个断点,通过debug运行后我们可以发现,configurations集合中就已经得到了127个自动配置类:
那么这些类究竟从何而来呢?我们需要探究一下getCandidateConfigurations()方法做了什么操作,它其实是调用了loadFactoryNames()方法:
1 | List<String> configurations = SpringFactoriesLoader.loadFactoryNames(this.getSpringFactoriesLoaderFactoryClass(), this.getBeanClassLoader()); |
最终调用的是loadSpringFactories()方法来得到一个Map集合:
1 | private static Map<String, List<String>> loadSpringFactories( ClassLoader classLoader) { |
可以看到,它其实是从 META-INF/spring.factories 文件中获取的组件,我们可以看看导入的依赖中:
在spring-boot-autoconfigure-2.3.7.RELEASE.jar的META-INF目录下就有一个spring.factories文件,打开看看文件内容:
1 | # Initializers |
文件里的内容其实就是在最开始需要注册的组件,这些组件都是一些配置类,只要项目一启动,Spring Boot就会将这些配置类全部注册到容器中。
按需开启自动配置
虽然配置类会被 Spring Boot 自动注册到容器中,但并不是每个配置类都会默认生效,SpringBoot会根据当前的场景按需开启自动配置。比如Thymeleaf模板引擎的自动配置类:
@ConditionalOnClass注解的作用是检查当前项目是否有指定的.class文件,若有则生效;否则不生效。因为我们并未引入Thymeleaf的依赖,导致TemplateMode.class和SpringTemplatengine.class都是不存在的,所以ThymeleafAutoCinfiguration并不会生效。
修改默认配置
既然SpringBoot帮助我们进行了大量的自动配置,那么对于特殊的一些应用场景,我们该如何修改它的默认配置呢?如果你不了解SpringBoot的配置原理,那么当你需要修改默认配置时,你肯定是束手无策的。我们可以找到SpringMVC的默认配置,看看SpringBoot是如何帮我们进行配置的:
@EnableConfigurationPropertie(WebMvcProperties.class)注解在之前也有介绍,它是用来开启指定类的配置绑定的,所以我们来看看WebMvcProperties类:
1 | @ConfigurationProperties(prefix = "spring.mvc") |
配置绑定的前缀时spring.mvc,所以我们若是想修改SpringBoot的默认配置,则必须要将前缀写为spring.mvc,至于我们可以修改哪些配置,只需要查看该类中有哪些成员变量即可,比如:
1 | public static class View { |
在WebMvcProperties类中有这样一个内部类,内部类中有prefix和suffix两个成员变量,它们是分别用来设置视图的前缀和后缀的,所以我们若想进行配置,则需要在配置文件中这样编写:
1 | spring.mvc.view.prefix=/views/ |
传统的Spring开发Web需要编写大量的配置,而使用SpringBoot将免去编写配置的操作,直接面向业务逻辑开发,一起来看看该如何使用SpringBoot进行Web开发吧!
Web开发
静态资源处理
Spring Boot默认设置了几个静态资源目录:
- /static
- /public
- /resources
- /META-INF/resources
这几个目录需要建立在类路径下,若如此做,则放置在这些目录下的静态资源可以被直接访问到。
也可以通过配置来设置资源的访问前缀:
1 | spring.mvc.static-path-pattern=/res |
此时若想访问静态资源,就必须添加res前缀才行。
我们还可以修改Spring Boot的默认资源路径,只需添加配置:
1 | spring.web.resources.static-locations=classpath:/myImg |
若如此做,则我们只能将静态资源放在myImg目录下,之前的所有静态资源目录都将失效。
欢迎页
Spring Boot提供了两种方式来实现欢迎页,第一种便是在资源目录放置欢迎页:
1 | <!DOCTYPE html> |
访问结果:
第二种方式是通过Controller处理/index请求:
1 | @Controller |
Favicon
Spring Boot也提供了自动设置网站图标的方式,只需要将名为 favicon.ico 的图片放在静态资源目录下即可:
Rest映射
在Spring Boot中,默认已经注册了HiddenHttpMethodFilter,所以可以直接编写Rest风格的url,只需在表单中添加一个_method属性的请求域即可:
1 | <!DOCTYPE html> |
编写Controller处理请求:
1 | @RestController |
最后需要在配置文件中开启对Rest的支持:
1 | spring.mvc.hiddenmethod.filter.enabled=true |
常用参数及注解
下面介绍Web开发中的一些常用参数和注解。
@PathVariable
该注解用于获取路径变量,比如:
1 | @GetMapping("/user/{id}") |
此时若请求url为http://localhost:8080/user/2,则获取到id值为2。
@RequestHeader
该注解用于获取请求头,比如:
1 | @GetMapping("/header") |
它还能够通过一个Map集合获取所有的请求头信息:
1 | @GetMapping("/header") |
@RequestParam
该注解用于获取请求参数,比如:
1 | @GetMapping("/param") |
此时若请求url为http://localhost:8080/param?name=zhangsan&age=20,则得到值`zhangsan:20` 。
@CookieValue
该注解用于获取Cookie值,比如:
1 | @GetMapping("/cookie") |
它还可以通过Cookie键名获取一个Cookie对象:
1 | @GetMapping("/cookie") |
@RequestBody
该注解用于获取获取请求体的值,比如:
1 | @PostMapping("/body") |
既然是获取请求体的值,那么只有Post请求才有请求体,所以编写一个表单:
1 | <!DOCTYPE html> |
通过该表单提交数据后,得到 username=admin&password=123 。
@RequestAttribute
该注解用于获取request域的数据,比如:
1 | @GetMapping("/success") |
通过键名即可获取request域中的数据。
@MatrixVariable
该注解用于获取矩阵变量,比如:
1 | @GetMapping("/matrix/{path}") |
对于该注解的使用,需要注意几点,首先矩阵变量是绑定在路径中的,所以请求映射中一定要携带一个${path};其次在SpringBoot中默认禁用掉了矩阵变量的功能,所以我们还需要手动去开启该功能:
1 | @Configuration |
此时访问请求url:http://localhost:8080/matrix/test;name=zhangsan;age=20, 得到结果:test---zhangsan:20 。
模板引擎
模板引擎是为了解决用户界面(显示)与业务数据(内容)分离而产生的。他可以生成特定格式的文档,常用的如格式如HTML、xml以及其他格式的文本格式。其工作模式如下:

常用的模板引擎:
jsp:是一种动态网页开发技术。它使用JSP标签在HTML网页中插入Java代码。
Thymeleaf : 主要渲染xml,HTML,HTML5而且与springboot整合。
Velocity:不仅可以用于界面展示(HTML.xml等)还可以生成输入java代码,SQL语句等文本格式。
FreeMarker:功能与Velocity差不多,但是语法更加强大,使用方便。
1、FreeMarker是一个用Java语言编写的模板引擎,它基于模板来生成文本输出。FreeMarker与Web容器无关,即在Web运行时,它并不知道Servlet或HTTP。它不仅可以用作表现层的实现技术,而且还可以用于生成XML,JSP或Java 等,在spring4.0中推荐使用thymeleaf来做前端模版引擎。
2、JSP技术spring boot 官方是不推荐的,原因有三:
2.1. 在tomcat上,jsp不能在嵌套的tomcat容器解析即不能在打包成可执行的jar的情况下解析
2.2. Jetty 嵌套的容器不支持jsp
2.3. Undertow
3、反正就是spring推荐themleaf,就学学themleaf。
18.8.31
在java领域,表现层技术主要有三种:jsp、freemarker、velocity。
jsp是大家最熟悉的技术
优点:
1、功能强大,可以写java代码
2、支持jsp标签(jsp tag)
3、支持表达式语言(el)
4、官方标准,用户群广,丰富的第三方jsp标签库
5、性能良好。jsp编译成class文件执行,有很好的性能表现
缺点:
jsp没有明显缺点,非要挑点骨头那就是,由于可以编写java代码,如使用不当容易破坏mvc结构。
velocity是较早出现的用于代替jsp的模板语言
优点:
1、不能编写java代码,可以实现严格的mvc分离
2、性能良好,据说比jsp性能还要好些
3、使用表达式语言,据说jsp的表达式语言就是学velocity的
缺点:
1、不是官方标准
2、用户群体和第三方标签库没有jsp多。
3、对jsp标签支持不够好
4、已经很久很久没有维护了。
freemarker
优点:
1、不能编写java代码,可以实现严格的mvc分离
2、性能非常不错
3、对jsp标签支持良好
4、内置大量常用功能,使用非常方便
5、宏定义(类似jsp标签)非常方便
6、使用表达式语言
缺点:
1、不是官方标准
2、用户群体和第三方标签库没有jsp多
选择freemarker的原因:
1、性能。velocity应该是最好的,其次是jsp,普通的页面freemarker性能最差(虽然只是几毫秒到十几毫秒的差距)。但是在复杂页面上(包含大量判断、日期金额格式化)的页面上,freemarker的性能比使用tag和el的jsp好。
2、宏定义比jsp tag方便
3、内置大量常用功能。比如html过滤,日期金额格式化等等,使用非常方便
4、支持jsp标签
5、可以实现严格的mvc分离
thymeleaf
Thymeleaf是个XML/XHTML/HTML5模板引擎,可以用于Web与非Web应用。Thymeleaf就是jsp的高端升级版
Thymeleaf的主要目标在于提供一种可被浏览器正确显示的、格式良好的模板创建方式,因此也可以用作静态建模。你可以使用它创建经过验证的XML与HTML模板。相对于编写逻辑或代码,开发者只需将标签属性添加到模板中即可。接下来,这些标签属性就会在DOM(文档对象模型)上执行预先制定好的逻辑。Thymeleaf的可扩展性也非常棒。你可以使用它定义自己的模板属性集合,这样就可以计算自定义表达式并使用自定义逻辑。这意味着Thymeleaf还可以作为模板引擎框架。
thymeleaf优点:静态html嵌入标签属性,浏览器可以直接打开模板文件,便于前后端联调。springboot官方推荐方案。
thymeleaf缺点:模板必须符合xml规范,就这一点就可以判死刑!太不方便了!js脚本必须加入/
spring boot 使用两个模板引擎
一 freemaker (来自学成在线第四天的页面静态化)
静态化之后上传到 gridFs 服务器上
目录如下

1.配置文件
application.yml

resources下templates 下 index_banner.ftl 模板页面

2.在test测试下写一个测试类 GridFsTest
@SpringBootTest
@RunWith(SpringRunner.class)
public class GridFsTest {
@Autowired
GridFsTemplate gridFsTemplate;
@Autowired
GridFSBucket gridFSBucket;
//存文件
@Test
public void testStore() throws FileNotFoundException {
//定义file
File file =new File("d:/index_banner.ftl");
//定义fileInputStream
FileInputStream fileInputStream = new FileInputStream(file);
ObjectId objectId = gridFsTemplate.store(fileInputStream, "index_banner.ftl");
System.out.println(objectId);
}
//取文件
@Test
public void queryFile() throws IOException {
//根据文件id查询文件
GridFSFile gridFSFile = gridFsTemplate.findOne(Query.query(Criteria.where("_id").is("5ce799bf840d5e6d88a0a0f7")));
//打开一个下载流对象
GridFSDownloadStream gridFSDownloadStream = gridFSBucket.openDownloadStream(gridFSFile.getObjectId());
//创建GridFsResource对象,获取流
GridFsResource gridFsResource = new GridFsResource(gridFSFile,gridFSDownloadStream);
//从流中取数据
String content = IOUtils.toString(gridFsResource.getInputStream(), "utf-8");
System.out.println(content);
}
}
详细解析页面静态化的流程实质是什么。。。。。。。。。。。。。。。。。。。。
二.thymeleaf
自己写的博客,使用的就是这个技术,但是看着有点麻烦,以后查看博客的时候再看使用
使用spring 框架使用freemaker
freemaker
(来自平优购的day12 的 商品详情页)感觉跟上面的spring boot集成的模式是一模一样的呀

最基础的配置文件,以及代码
1 | 1.3.3生成文件 |
执行后,在D盘根目录即可看到生成的test.html ,打开看看
其实静态化的流程都是一样的,
只是在第四步的时候,是注入 模板对象@Autotuy ReTemplate reTemplate,
第五步的时候是注入其他的依赖 获取页面详情页所需要的数据 然后 数据+模板引擎=新的页面
定时器
创建定时任务主要有两种创建方式:一、基于注解(@Scheduled) 二、基于接口(SchedulingConfigurer)
cron表达式
一个cron表达式有至少6个(也可能7个)有空格分隔的时间元素。crontab参数* * * * * * *
第一个* second: 区间为 0 – 59 , - * /
第二个* minute: 区间为 0 – 59 , - * /
第三个* hour: 区间为0 – 23 , - * /
第四个* day-of-month: 区间为0 – 31 , - * / ? L W C
第五个* month: 区间为1 – 12 或JAN-DEC 1 是1月 12是12月 , - * /
第六个* Day-of-week: 区间为0 – 7 或SUN-SAT 周日可以是0或7 , - * / ? L C #
第七个* (可选)year:区间为1970-2099 , - * /
1.有些子表达式能包含一些范围或列表
例如:子表达式(天(星期))可以为 “MON-FRI”,“MON,WED,FRI”,“MON-WED,SAT”
2.* 字符代表所有可能的值:表示匹配该域的任意值,假如在Minutes域使用*, 即表示每分钟都会触发事件
3./字符用来指定数值的增量:表示起始时间开始触发,然后每隔固定时间触发一次,例如在Minutes域使用5/20,则意味着5分钟触发一次,而25,45等分别触发一次.
4.?字符仅被用于天(月)和天(星期)两个子表达式,表示不指定值(也就是第四位和第六位只能指定一个值,另一个不指定的就为?)
只能用在DayofMonth和DayofWeek两个域。它也匹配域的任意值,但实际不会。因为DayofMonth和DayofWeek会相互影响。
例如想在每月的20日触发调度,不管20日到底是星期几,则只能使用如下写法: 13 13 15 20 * ?, 其中最后一位只能用?,而不能使用,如果使用表示不管星期几都会触发,实际上并不是这样。
5.-表示范围,例如在Minutes域使用5-20,表示从5分到20分钟每分钟触发一次
6.,表示列出枚举值值。例如:在Minutes域使用5,20,则意味着在5和20分每分钟触发一次
7.L字符仅被用于天(月)和天(星期)两个子表达式,它是单词“last”的缩写
在天(月)子表达式中,“L”表示一个月的最后一天
在天(星期)自表达式中,“L”表示一个星期的最后一天,也就是SAT
如果在“L”前有具体的内容,它就具有其他的含义了
例如:
在DayofWeek域使用5L,意味着在最后的一个星期四触发
“6L”表示这个月的倒数第6天,“FRIL”表示这个月的最一个星期五
注意:在使用“L”参数时,不要指定列表或范围,因为这会导致问题
W表示有效工作日(周一到周五),只能出现在DayofMonth域,系统将在离指定日期的最近的有效工作日触发事件。
例如:在 DayofMonth使用5W,如果5日是星期六,则将在最近的工作日:星期五,即4日触发。如果5日是星期天,则在6日(周一)触发;如果5日在星期一到星期五中的一天,则就在5日触发。另外一点,W的最近寻找不会跨过月份
LW 这两个字符可以连用,表示在某个月最后一个工作日,即最后一个星期五
#用于确定每个月第几个星期几,只能出现在DayofMonth域。例如在4#2,表示某月的第二个星期三
一、静态定时任务(基于注解)
基于注解@Scheduled默认为单线程,开启多个任务时,任务的执行时机会受上一个任务执行时间的影响
当定时任务增多,如果一个任务卡死,会导致其他任务也无法执行
1 | @Configuration //1.主要用于标记配置类,兼备Component的效果。 |
启动应用,可以看到控制台的信息打印出了语句。
使用Scheduled 很方便,但缺点是当我们调整了执行周期的时候,需要重启应用才能生效,这多少有些不方便。为了达到实时生效的效果,可以使用接口来完成定时任务。
二、动态定时任务(基于接口)
数据库准备好数据之后,编写定时任务,注意这里添加的是TriggerTask,目的是循环读取我们在数据库设置好的执行周期,以及执行相关定时任务的内容
1 |
|
注意: 如果在数据库修改时格式出现错误,则定时任务会停止,即使重新修改正确;此时只能重新启动项目才能恢复
三、多线程定时任务
1 | //@Component注解用于对那些比较中立的类进行注释; |

每一个任务都是在不同的线程中,第一个定时任务和第二个定时任务互不影响;
并且,由于开启了多线程,第一个任务的执行时间也不受其本身执行时间的限制,所以需要注意可能会出现重复操作导致数据异常
定时任务
Timer:
这是java自带的java.util.Timer类,这个类允许你调度一个java.util.TimerTask任务。使用这种方式可以让你的程序按照某一个频度执行,但不能在指定时间运行。一般用的较少。
在java中一个完整的定时任务可以用Timer和TimerTask两个类配合完成。
Timer是一种工具,线程用其安排在后台线程中执行的任务,可安排任务执行一次或者定期重复执行。
TimerTask是由Timer安排执行一次或者重复执行的任务。
Timer中提供了四个方法:
(1)schedule(TimerTask task,Date time)——安排在指定的时间执行指定的任务
(2)schedule(TimerTask task,Date firstTime,long period)——安排指定的任务在指定的时间开始进行重复的固定延迟执行
(3)schedule(TimerTask task,long delay)——安排在指定延迟后执行指定的任务
(4)schedule(TimerTask task,long delay,long period)——安排指定的任务在指定的延迟后开始进行重复的固定速率执行
注意:Timer对于系统时间的改变非常敏感,它对调度的支持是基于绝对时间而不是相对时间。
Timer线程是不会捕获异常的,多线程并行处理定时任务时,Timer运行多个TimerTask时,只要其中之一没有捕获抛出的异常,其他任务便会自动终止运行。同时Timer也不会重新恢复线程的执行,它会错误的认为整个Timer线程都会取消,已经被安排但尚未执行的TimerTask也不会再执行了,新的任务也不能被调度。因此,如果TimerTask抛出未检查的异常,Timer将会产生无法预料的行为。
1 | public class TestTimer { |
ScheduledExecutorService:
jdk自带的一个类;是基于线程池设计的定时任务类,每个调度任务都会分配到线程池中的一个线程去执行,也就是说,任务是并发执行,互不影响。
Timer是基于绝对时间的,对系统时间比较敏感,而ScheduledExecutor则是基于相对时间。
Timer的内部只有一个线程,如果有多个任务的话就会顺序执行,这样我们的延迟时间和循环时间就会出现问题。而ScheduledThreadPoolExecutor内部是个线程池,可以支持多个任务并发执行,在对延迟任务和循环任务要求严格的时候,就需要考虑使用ScheduledExecutor了。
针对Timer类存在的缺陷,Java 5 推出了基于线程池设计的 ScheduledExecutor,ScheduledExecutor的设计思想是每一个被调度的任务都会由线程池中一个线程去执行,因此任务是并发的,相互之间不会受到干扰,只有当任务的时间到来时,ScheduledExecutor才会真正启动一个线程,其余时间ScheduledExecutor都是处于轮询任务的状态。如果我们设定的调度周期小于任务运行时间,该任务会被重复添加到一个延时任务队列,所以同一时间任务队列中会有多个任务待调度,线程池会首先获取优先级高的任务执行。效果就是任务运行多长时间,调度时间就会变为多久,因为添加到任务队列的任务的延时时间每次都是负数,所以会被立刻执行。
1 | public class TestScheduledExecutorService { |
Spring Task:
Spring3.0以后自带的task,可以将它看成一个轻量级的Quartz,而且使用起来比Quartz简单许多。
也就是上面的那个定时器
Spring提供的注解,优点就是配置简单,依赖少,缺点是同一个task,如果前一个还没跑完后面一个就不会触发,不同的task也不能同时运行。因为scheduler的默认线程数为1,配置pool-size为2的话,会导致同一个task前一个还没跑完后面又被触发的问题,不支持集群等。
Quartz
Quartz 是一个完全由 Java 编写的开源作业调度框架,它可以集成在几乎任何Java应用程序中进行作业调度。
Quartz 可以与 J2EE 与 J2SE 应用程序相结合也可以单独使用。
Quartz 允许程序开发人员根据时间的间隔来调度作业。
Quartz 实现了作业和触发器的多对多的关系,还能把多个作业与不同的触发器关联。
Quartz的运行环境
Quartz 可以运行嵌入在另一个独立式应用程序。
Quartz 可以在应用程序服务器(或 servlet 容器)内被实例化,并且参与 XA 事务。
Quartz 可以作为一个独立的程序运行(其自己的 Java 虚拟机内),可以通过 RMI 使用。
Quartz 可以被实例化,作为独立的项目集群(负载平衡和故障转移功能),用于作业的执行。
拦截器
一个完善的Web应用一定要考虑安全问题,比如,只有登录上系统的用户才能查看系统内的资源,或者只有具备相关权限,才能访问对应的资源,为此,我们需要学习一下拦截器,通过拦截器我们就能够实现这些安全认证。
这里以登录检查为例:
1 | public class LoginInterceptor implements HandlerInterceptor { |
编写好拦截器后需要将其配置到容器中:
1 | @Configuration |
需要指定该拦截器需要拦截哪些资源,需要放行哪些资源,这样一个简单的登录校验就完成了。
文件上传
Spring Boot中该如何实现文件上传呢?现有如下的一个表单:
1 | <!DOCTYPE html> |
编写控制方法:
1 | @RestController |
通过@RequestPart注解即可将上传的文件封装到MultipartFile中,通过该对象便可以获取到文件的所有信息。输出结果:
若是上传多个文件,则先修改表单信息:
1 | <form action="/upload" method="post" enctype="multipart/form-data"> |
在文件框位置添加multiple属性即可支持多文件上传,然后修改控制器代码:
1 | @PostMapping("/upload") |
若是需要将上传的文件保存到服务器,则可以如此做:
1 | @PostMapping("/upload") |
因为Spring Boot默认的文件上传大小限制为1MB,所以只要文件稍微大了一点就会上传失败,为此,可以修改SpringBoot的默认配置:
1 | spring.servlet.multipart.max-file-size=30MB # 配置单个文件上传大小限制 |
错误处理
默认情况下,SpringBoot应用出现了异常或错误会自动跳转至/error页面,也就是这个熟悉的页面:
然而一般情况下,我们都不会选择出异常时显示这个页面,而是想要显示我们自己定制的页面,为此,我们可以在/static或/templates目录下新建一个error目录,并在/error目录下放置命名为4xx、5xx的页面,SpringBoot会自动帮助我们解析。
此时当出现5xx的异常时,SpringBoot会自动跳转至5xx.html页面,当然你也可以对每个状态码都做一个页面进行对应,比如放置500.html、501.html、502.html文件,当服务器出现对应的异常时,就会跳转至对应的页面。
健康检查、审计、统计和监控
Spring Boot Actuator可以帮助你监控和管理Spring Boot应用,比如健康检查、审计、统计和HTTP追踪等。所有的这些特性可以通过JMX或者HTTP endpoints来获得
Actuator同时还可以与外部应用监控系统整合,比如 Prometheus, Graphite, DataDog, Influx, Wavefront, New Relic等。这些系统提供了非常好的仪表盘、图标、分析和告警等功能,使得你可以通过统一的接口轻松的监控和管理你的应用。
Actuator使用Micrometer来整合上面提到的外部应用监控系统。这使得只要通过非常小的配置就可以集成任何应用监控系统
1 | <dependencies> |
Actuator创建了所谓的endpoint来暴露HTTP或者JMX来监控和管理应用
/healthendpoint,提供了关于应用健康的基础信息。
/metricsendpoints展示了几个有用的度量信息,比如JVM内存使用情况、系统CPU使用情况、打开的文件等等。
/loggersendpoint展示了应用的日志和可以让你在运行时改变日志等级
值得注意的是,每一个actuator endpoint可以被显式的打开和关闭。此外,这些endpoints也需要通过HTTP或者JMX暴露出来,使得它们能被远程进入
数据层
JDBC
若想使用原生的JDBC进行开发,SpringBoot已经为我们配置好了JDBC的相关信息,只需要引入依赖:
1 | <dependency> |
Spring Boot 底层自动配置了HikariDataSource数据源,所以我们只需指定数据源的地址、用户名和密码即可:
1 | spring.datasource.url=jdbc:mysql: |
因为SpringBoot已经自动配置好了JdbcTemplate,所以我们直接使用就可以了:
1 | @SpringBootTest |
Druid
若是不想使用Spring Boot底层的数据源,我们也可以修改默认配置,以Druid数据源为例,首先引入依赖:
1 | <dependency> |
并对Druid进行配置:
1 | # 开启Druid的监控页功能 |
此时访问http://localhost:8080/druid,将会来到Druid的监控页:
MyBatis
接下来我们将整合MyBatis框架,并介绍它的简单使用。首先引入依赖:
1 | <dependency> |
然后编写Mapper接口:
1 | @Mapper |
编写Mappe配置文件:
1 | <?xml version="1.0" encoding="UTF-8"?> |
最后配置一下MyBatis:
1 | # 配置Mapper配置文件的位置 |
这样就可以使用MyBatis了:
1 | @SpringBootTest |
Redis
若是想要整合Redis,也非常地简单,首先引入依赖:
1 | <dependency> |
然后进行配置:
1 | # 主机地址 |
只需要配置Redis的主机地址就可以操作Redis了,操作步骤如下:
1 | @SpringBootTest |
若是想使用Jedis操作Redis,则需要导入Jedis的依赖:
1 | <dependency> |
并配置:
1 | spring.redis.client-type=jedis |
Filter+ThreadLocal
由于jwt的出现,使请求方法的参数中不再携带用户的标识,而是将含有用户信息的token放入请求头中,在该请求进入业务之前就要进行层层过滤拦截,这时候就会牵扯出来了一个问题,如何在当前请求的线程中保存该请求用户的信息。
ThreadLocal
ThreadLocal叫做线程变量,意思是ThreadLocal中填充的变量属于当前线程,该变量对其他线程而言是隔离的。ThreadLocal为变量在每个线程中都创建了一个副本,那么每个线程可以访问自己内部的副本变量。所以设计思路是,我们可以将每个访问的请求拦截下,为其分配线程变量,就先是全局变量一样,在这次请求访问的所有作用域处都可以从中拿出变量进行使用:
1 | /** |
我们可以看出LocalThread的应用场景:
1、在进行对象跨层传递的时候,使用ThreadLocal可以避免多次传递,打破层次间的约束。
2、线程间数据隔离
3、进行事务操作,用于存储线程事务信息。
4、数据库连接,Session会话管理。
- Filter中的使用
1 | //接口业务均在api下 |
在拦截器中的使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// access为自定义权限注解,if条件指该接口访问权限至少要登录(具备token)
if (access.level().getCode() >= AccessLevel.LOGIN.getCode()) {
//这里可以直接在拦截器中再次获取用户信息
User user = UserUtils.getLoginUser();
if (user == null || user.getId() == null) {
response.setStatus(401);
logger.info("access " + method.getName() + " Not logged in");
return false;
}
if (user.getType() < access.level().getCode()) {
response.setStatus(403);
logger.info("access " + method.getName() + " No authority");
return false;
}
}1
2
3
4
5
6
7
8
9
4. Controller/Service层的使用
```java
//在Controller或是Service中依然可以通过线程变量或取该用户信息
User user = UserUtils.getLoginUser();
long userId = UserUtils.getLoginUserId();我们可以看到,在进行对象跨层传递的时候,使用ThreadLocal可以避免多次传递,打破层次间的约束。使用起来确实十分方便,但是也要有注意的地方:
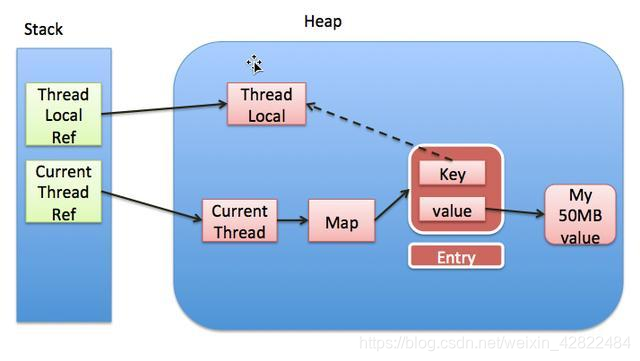
上图详细的说明了ThreadLocal和Thread以及ThreadLocalMap三者之间的关系。
1、Thread中有一个map,即ThreadLocalMap。
2、ThreadLocalMap的key是ThreadLocal,值是我们自己赋值的。
3、ThreadLocal是一个弱引用,当为null时侯,会被当成垃圾回收。
4、如果我们ThreadLocal是null了,也就是要被垃圾回收器回收了,但是此时我们的ThreadLocalMap生命周期和Thread的一样,它不会回收,这时候就出现了一个现象。那就是ThreadLocalMap的key没了,但是value还在,这就造成了内存泄漏。
解决办法:使用完ThreadLocal后,即拦截器的后处理,执行remove操作,避免出现内存溢出情况。
1 |
|
ApplicationRunner(一个spring容器启动完成执行的类)
在项目中,可能会遇到这样一个问题:在项目启动完成之后,紧接着执行一段代码。
在SpringBoot中,提供了一个接口:ApplicationRunner。
该接口中,只有一个run方法,他执行的时机是:spring容器启动完成之后,就会紧接着执行这个接口实现类的run方法。
1 | @Component |
这里有几点说明:
- 这个实现类,要注入到spring容器中,这里使用了@Component注解;
- 在同一个项目中,可以定义多个ApplicationRunner的实现类,他们的执行顺序通过注解@Order注解或者再实现Ordered接口来实现。
- run方法的参数:ApplicationArguments可以获取到当前项目执行的命令参数。(比如把这个项目打成jar执行的时候,带的参数可以通过ApplicationArguments获取到);
- 由于该方法是在容器启动完成之后,才执行的,所以,这里可以从spring容器中拿到其他已经注入的bean。
新建一个springboot项目
一、创建项目
1.File->new->project;

2.选择“Spring Initializr”,点击next;(jdk1.8默认即可)

选择default可能会因为网速导致项目新建失败。
不选择默认的Default,而是适用Custom,输入aliyun的镜像节点:http://start.aliyun.com
3.完善项目信息,组名可不做修改,项目名可做修改;最终建的项目名为:test,src->main->java下包名会是:com->example->test;点击next;

4.Web下勾选Spring Web Start,(网上创建springboot项目多是勾选Web选项,而较高版本的Springboot没有此选项,勾选Spring Web Start即可,2.1.8版本是Spring Web);Template Englines勾选Thymeleaf;SQL勾选:MySQL Driver,JDBC API 和 MyBatis Framework三项;点击next;

5.选择项目路径,点击finish;打开新的窗口;
